YARN学习笔记
[TOC]
1. YARN产生背景
1.1 Hadoop 1.x中MapReduce存在的问题
Hadoop 1.x时,还没有YARN。MapReduce架构采用的是Master/Slave架构,一个JobTracker带多个TaskTracker。提交作业时客户端直接与MapReduce的JobTracker进行通信。
- JobTracker主要的功能是资源的管理与作业的调度。
- TaskTracker
- 定期(通过心跳)向JobTracker汇报本节点的健康状况、资源使用情况、作业执行情况。
- 接收来自JobTracker的命令:启动任务、杀死任务
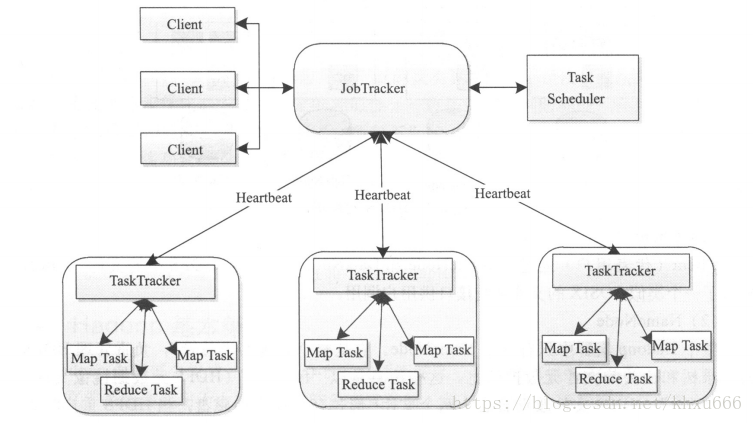
存在采用的Master的问题:
- 单点故障:整个集群只有1个JobTracker。
- JobTracker要接受各个TaskTracker与client的通信请求,节点压力大。
- JobTracker承担了多种职责,且只能接受MapReduce的作业,不易扩展。
1.2 提高资源利用率和降低运维成本的诉求
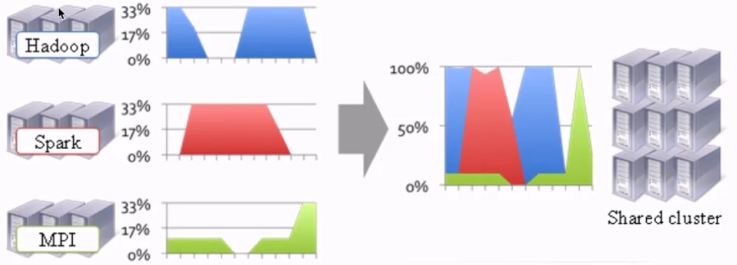
我们如果不同的作业类型(Hadoop、Spark、MPI)如果使用不同的集群,会需要更多的资源,同时资源利用率也比较低、运维需要维护多个集群,还存在跨网络的问题。
如何将多种作业类型放在同一个集群,共享数据、计算资源,成为日益迫切的诉求。
1.3 YARN的诞生
基于上述两节,催生了YARN。可以在YARN上运行多种不同的计算框架。不同计算框架可以共享同一个HDFS集群上的数据,享受整体的资源调度。
所谓的多种框架运行在YARN,就是常说的xxx on YARN,比如Spark/MapReduce/Flink on YARN. xxx on YARN的好处:与其他计算框架共享集群资源,按资源需要分配,进而提高集群资源的利用率。
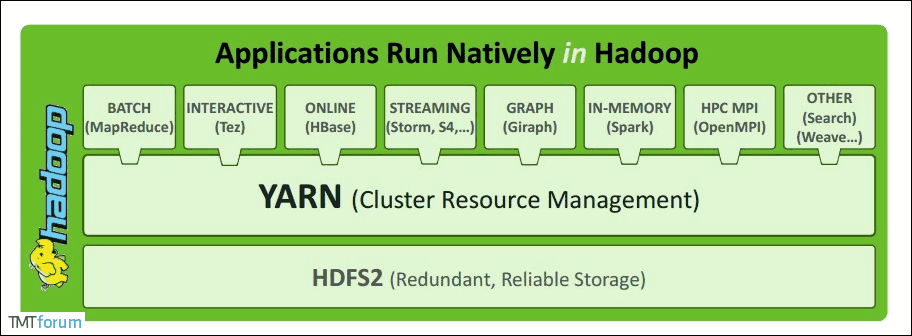
2. YARN概述
官网地址:https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html
- YARN的名称其实是Yet Another Resource Negoitiator的首字母缩写;
- YARN是一个通用的资源管理系统;
- 为上层的应用提供统一的资源管理和调度能力
- 监控Node Manager,一旦某个Node Manager,那么该Node Manager上运行的任务,那么该Node Manager上运行的任务需要高速我们的Application Master
3. YARN架构
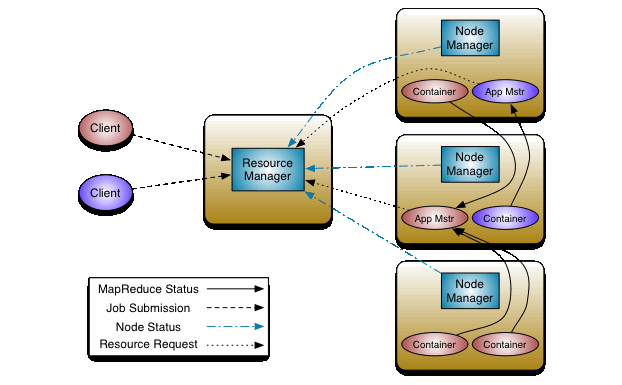
Resource Manager:
- 同一时间,整个集群提供服务的Resource Manager只有一个,负责集群资源的统一管理与调度;
- 处理客户端的请求:提交一个作业、杀死一个作业;
- 监控Node Manager,一旦某个Node Master挂了,那么该Node Manager上运行的任务需要高速我们的Application Master如何进行重启。
Node Manager:
- 整个集群有多个,负责自己本身节点资源管理和使用;
- 定时向Resource Manager本节点资源使用情况;
- 接收并处理来自Resource Manager的各种命令:启动container;
- 处理来自Application Master的命令;
- 单个节点的资源管理。
Application Master:
- 每个应用程序对应一个:MapReduce、Spark,负责应用程序的管理;
- 为应用程序向Resource Manager申请资源(core、memory),分配给内部task;
- 需要与Node Manager通信:启动/停止task,task是运行在container里面,Application Master也运行在container里面。
Container:
- 封装了CPU、Memory等资源的一个容器
- 是一个任务运行环境的抽象
Client:
- 提交作业
- 查询作业的运行进度
- 杀死作业
4. YARN执行流程
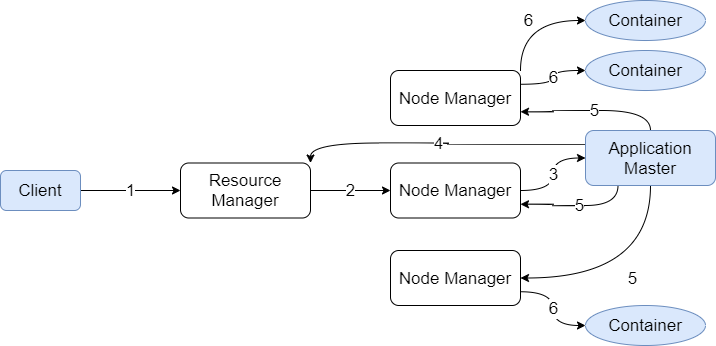
- 用户向YARN提交作业;
- Resource Manager为第一个container分配节点,这个container用来启动application master;
- Node Manager为application master启动container;
- Application Master向Resource Manager进行注册。此时Client就可以通过Resource Manager查询任务的运行情况了。同时,Application Master为作业申请作业所需的资源;
- Application Master申请到资源之后向Node Manager申请运行任务所需要的资源;
- Node Manager为Application Master创建任务对应的container。
上述流程是一个通用YARN任务流程,只需要按照YARN接口实现不同的Application Master,比如实现Map Reduce Application Master,或者Spark Application Master。
5. YARN环境搭建
5.1 配置YARN
etc/hadoop/mapred-site.xml: 指定map reduce跑在yarn之上。
1 | <configuration> |
etc/hadoop/yarn-site.xml
1 | <configuration> |
5.2 启动Resource Manager与Node Manager
1 | sbin/start-yarn.sh |
5.3 验证
方法1:jps:
1 | liulixiang@DESKTOP-34LMJFE:/mnt/d/app/hadoop-2.10.1/sbin$ jps -l |
方法2:访问:ResourceManager - http://localhost:8088/
5.4 停止
1 | ./stop-yarn.sh |
6. 提交作业到YARN上执行
1 | share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar |
hadoop提供了一个命令提交作业:
1 | hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar pi 2 3 |