HDFS学习笔记
[TOC]
1. HDFS 概述及设计目标
Hadoop设计目标:
- 非常巨大的分布式文件系统
- 运行在普通廉价的硬件上
- 易扩展、为用户提供性能不错的文件存储服务
2. HDFS架构
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html

HDFS采用1个Master(NameNode/NN) 带N个Slaves(DataNode/DN)架构。同时YARN、HBase也是一个Master带多个Slave。
1个文件会被拆分成多个Block。(BlockSize默认是128M)。比如一个130M的文件会被分成128M和2M的Block。
NameNode(NN):
- 响应客户端请求
- 负责元数据(文件名、副本系数、Block存放的DN)的管理
DataNode(DN):
- 储存用户的文件对应的数据块(Block)
- 要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
A typical deployment has a dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNode software. The architecture does not preclude running multiple DataNodes on the same machine but in a real deployment that is rarely the case.
3. HDFS副本机制
All blocks in a file except the last block are the same size.
An application can specify the number of replicas of a file. The replication factor can be specified at file creation time and can be changed later. Files in HDFS are write-once (except for appends and truncates) and have strictly one writer at any time.
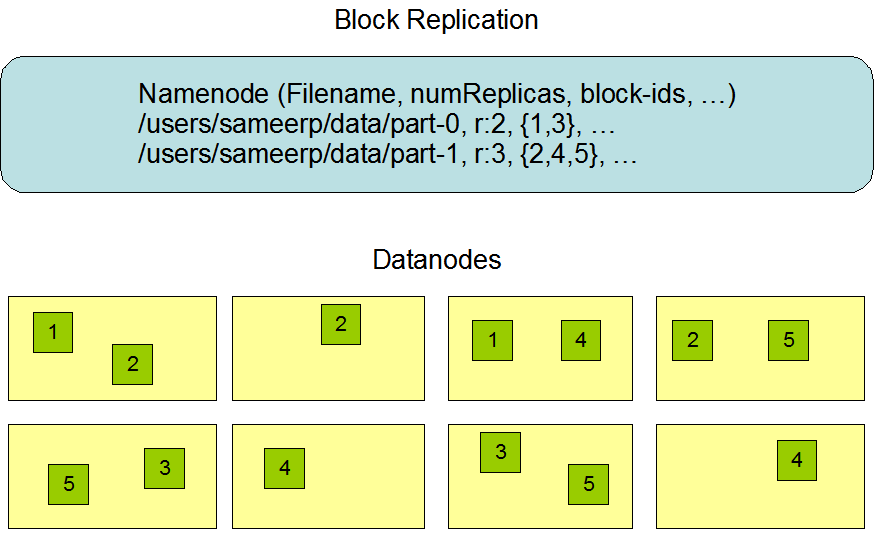
副本存放策略:副本放到不同机架(Rack)的不同节点上。
4. HDFS环境搭建
4.1 Hadoop伪分布式安装(Pseudo-Distributed Operation)
环境准备:
- JDK安装,定义
JAVA_HOME与PATH=$JAVA_HOME/bin:$PATH - 安装SSH:
sudo yum install ssh- 配置免密登录(给DataNode与NN)
ssh-keygen -t rsa, 生成了.ssh文件夹 cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys- 测试连接:
ssh localhost或ssh hadoop000(hadoop000是hostname)
下载解压Hadoop,修改配置文件:
- 下载CDH:
hadoop-2.6.0-cdh5.7.0.tar.gz tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C /opt/cd hadoop-2.6.0-cdh5.7.0/- 查看目录:
- bin:主要是客户端访问的脚本(包含windows下的访问脚本)
- etc: 配置文件,非常重要
- sbin: 启动集群
- share/hadoop/:样例包
- 修改
etc/hadoop-env.sh,设置JAVA_HOME
etc/hadoop/core-site.xml(配置HDFS默认文件地址)
1 | <configuration> |
etc/hadoop/hdfs-site.xml(设置副本系数)
1 | <configuration> |
etc/hadoop/slaves(配置master node对应的slave node hostname)
配置后启动:
- 格式化文件系统(仅第一次执行):
bin/hdfs(or hadoop) namenode -format(客户端操作) - 启动NameNode进程与DataNode进程:
sbin/start-dfs.shHadoop daemon log会被写入$HADOOP_LOG_DIR文件夹,默认为$HADOOP_HOME/logs - 验证是否启动成功
jps,看到DataNode,NameNode与SecondaryNameNode- http://hadoop000:50070
停止hdfs: sbin/stop-dfs.sh
5. HDFS Shell
为了方便使用,配置环境变量:HADOOP_HOME, PATH=$HADOOP_HOME/bin:$PATH
hdfs是客户端。
hadoop dfs
ls: hadoop fs -ls, hadoop fs -ls -R
mkdir: hadoop fs -mkdir -p /a/test
put: hadoop fs -put hello.txt /
get: hadoop fs -get /a/test/a.txt
rm: hadoop fs -rm /a/test
text: 查看,hadoop fs -text /hello.txt
也可以在浏览器菜单中utilities中查看文件
6. Java API操作HDFS
7. HDFS文件读写流程
通过漫画来学习HDFS文件的读写流程,PDF版本可以通过这里下载
三个角色:
- 客户端:发起读写请求
- NameNode: 只有1个,负责协调(coordinate)
- DataNode:存储数据,有多个
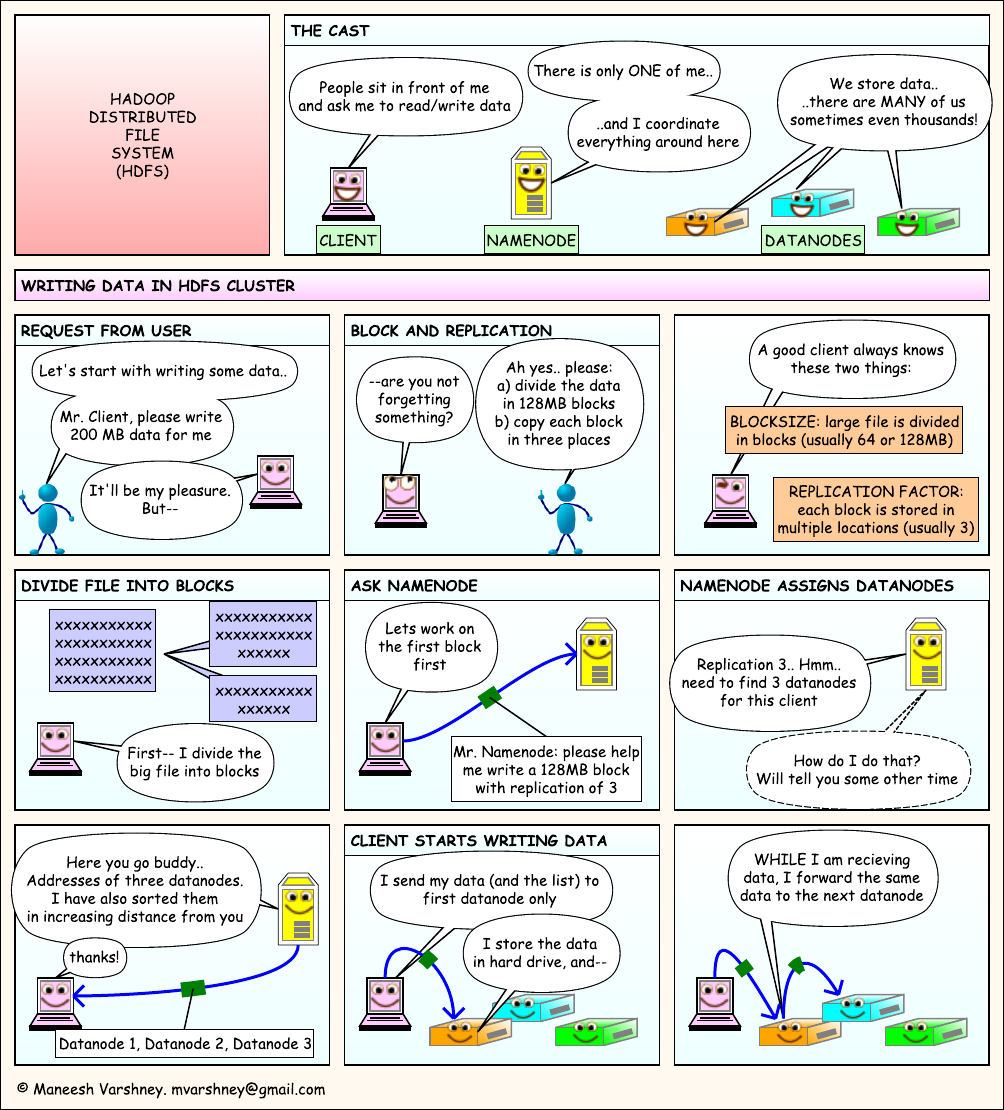

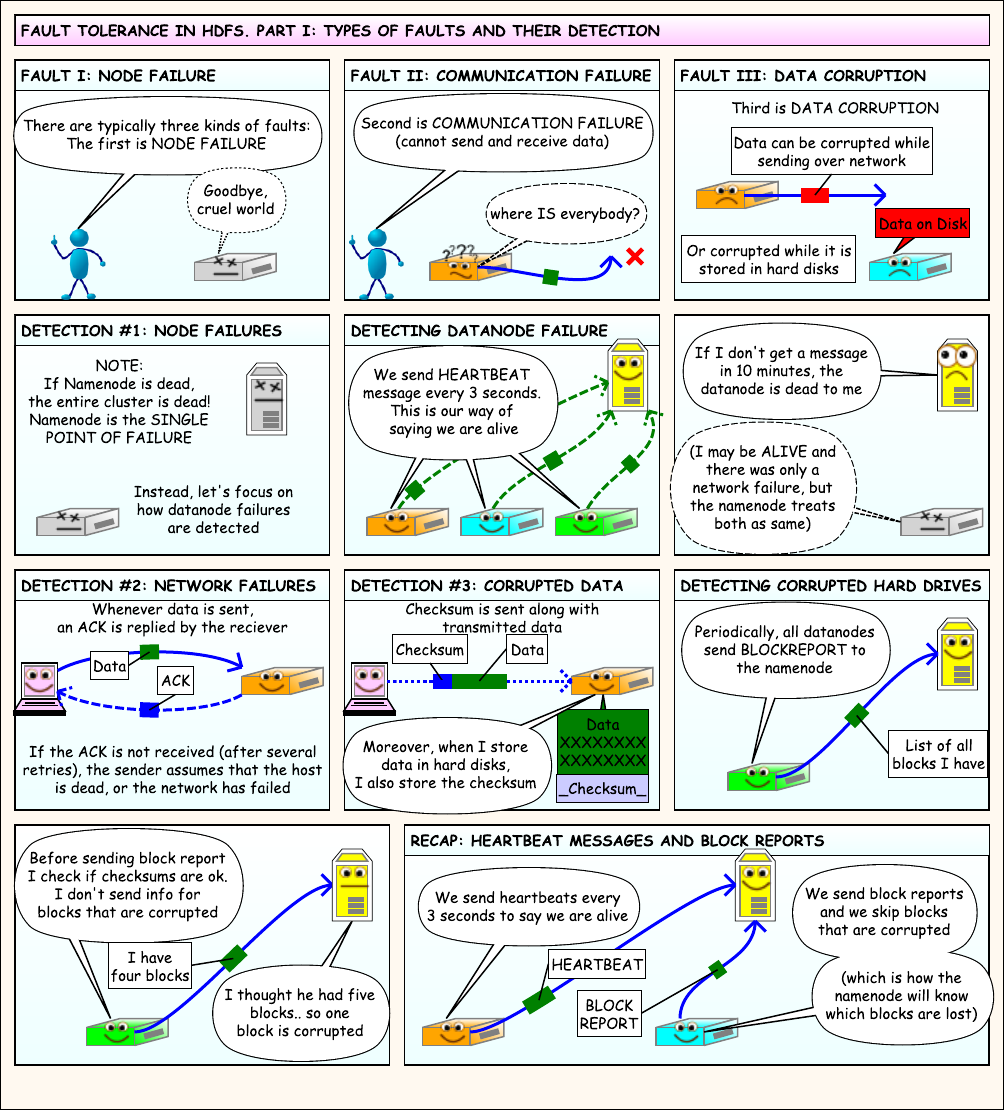

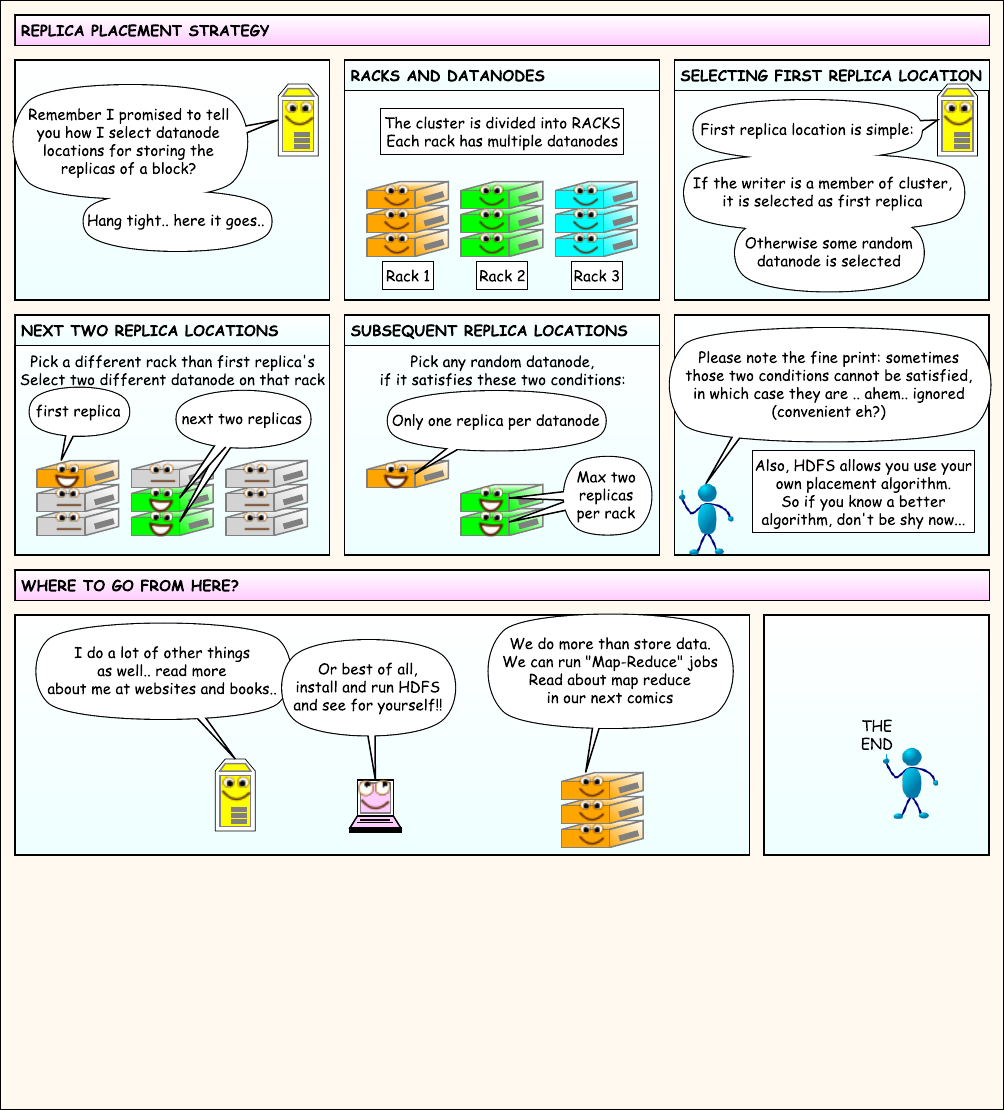
8. HDFS优缺点
优点:
- 数据冗余、硬件容错
- 适合存储大文件
- 可构建在廉价机器上
缺点:
- 不适合低延迟数据访问:数据比较大
- 不适合小文件数据存储:占用太多NameNode中内存存储元数据,对NameNode压力也越大