LLM Foundations: Vector Databases for Caching and Retrieval Augmented Generation (RAG)
Introduction
- Status: Finished
- Author: Kumaran Ponnambalam
- Publishing/Release Date: February 23, 2024
- Publisher: Linkedin
- Link: https://www.linkedin.com/learning/llm-foundations-vector-databases-for-caching-and-retrieval-augmented-generation-rag/genai-with-vector-databases?resume=false&u=3322
- Type: Courses
- Start Date: May 28, 2024
- End Date: June 9, 2024
Scope
- Vector and vector search concepts review
- Concepts and Setup of Milvus DB
- Milvus DB data manipulation and search
- Vector DB as a LLM cache
- Vector DB for Retrieval Augmented Generation (RAG)
Prerequisites
- NLP for Machine learning
- LLM and embeddings
- Python, jupyter notebooks, docker
- LangChain
Introduction to Vector Databases
What is a vector?
A vector is an object that has both magnitude (size, quantity) and direction (line, angle, trend)
Vectors in Programming:
- A one-dimensional data structure
- Homogeneous (has elements of the same type)
- Defined position for each element
- Storage / access different from lists and arrays
- For example:
[1.0, 2.1, 2.2]
Vectorization in NLP
- ML algorithm can only handle numeric data
- Text data needs to be converted to equivalent numeric representations for ML purposes
- Vectorization converts text to numeric values
- Captures structure and / or semantics of original text
Vectorization Techniques
- Bag of words
- TF-IDF (text frequency - inverse document frequency)
- Creates sparse matrices of documents
- Word embeddings
- Captures semantic information in vectors
- Sentence embeddings
- Popular with large language model (LLM)-based applications
Vector similarity search
Each vector has a series of data points
A sentence can be a vector of its embeddings
Similarity measures how close two vectors are
Distance measures are used to measure similarity
Euclidean distance (L2)
$$
\begin{equation}d(i,j)=\sqrt {(p_1-q_1)^2 + (p_2-q_2)^2+…+(p_n-q_n)^2}\end{equation}
$$Inner product (IP)
$$
\begin{equation}A \cdot B = \sum_{i=1}^{n} {A_i}{B_i}\end{equation}
$$Cosine similarity (COSINE)
$$
\begin{equation}\cos(A,B) = \frac{A\cdot B}{|A||B|}=\frac{\sum_{i=1}^{n}{A_iB_i}}{\sqrt{\sum_{i=1}^{n}A_i^2}\cdot\sqrt{\sum_{i=1}^{n}B_i^2}}\end{equation}
$$
Vectorize strings using any of the vectorization techniques
- List of strings to search
- Query string to compare against
Compare vectors using approximate nearest neighbor (ANN) algorithms
Use distance measures with ANN to determine similarity
Retrieve top-K results ordered by similarity
Vector databases
Vector databases are specialized database products that are optimized for storage and querying of vector data.
- Vector Database Features
- Support for vector data types
- Support for regular datatypes
- CRUD operations on vector and scalar data
- Semantic search on vector data
Vectors Databases Available
| Open Source | Commercial | |
|---|---|---|
| Specialized Vector Databases | Milvus, Chroma, Vespa, Qdrant | Pinecone, Weaviate |
| General databases supporting vector search | PostgreSQL, Cassandra, OpenSearch | Elasticsearch, Redis, SingleStore |
Pros and cons of vector databases
Vector DB Advantages
- Semantic search support (ANN, distance measures)
- Bulk data loading
- Indexing
- Efficient data retrieval
- Scalability
- Clustering and fault tolerance
Vector DB Shortcomings
- Limited support for traditional querying
- Transactional support
- Insert latency when handling large datasets
- Computationally expensive for semantic searches
- Memory intensive
- Integrations
Milvus Databases Concepts
Introduction to Milvus DB
Milvus is a specialized database that is built for storing, indexing, and searching vectors.
- Open source and commercial
- Standalone, cluster, and managed (Zilliz cloud) options
- Highly scalable for vector storage and search
- Euclidean distance (L2), inner product (IP) and COSINE metrics
- Hybrid data storage and search
- Access with SDKs (Python, Node.js, Go, Java)
Milvus architecture
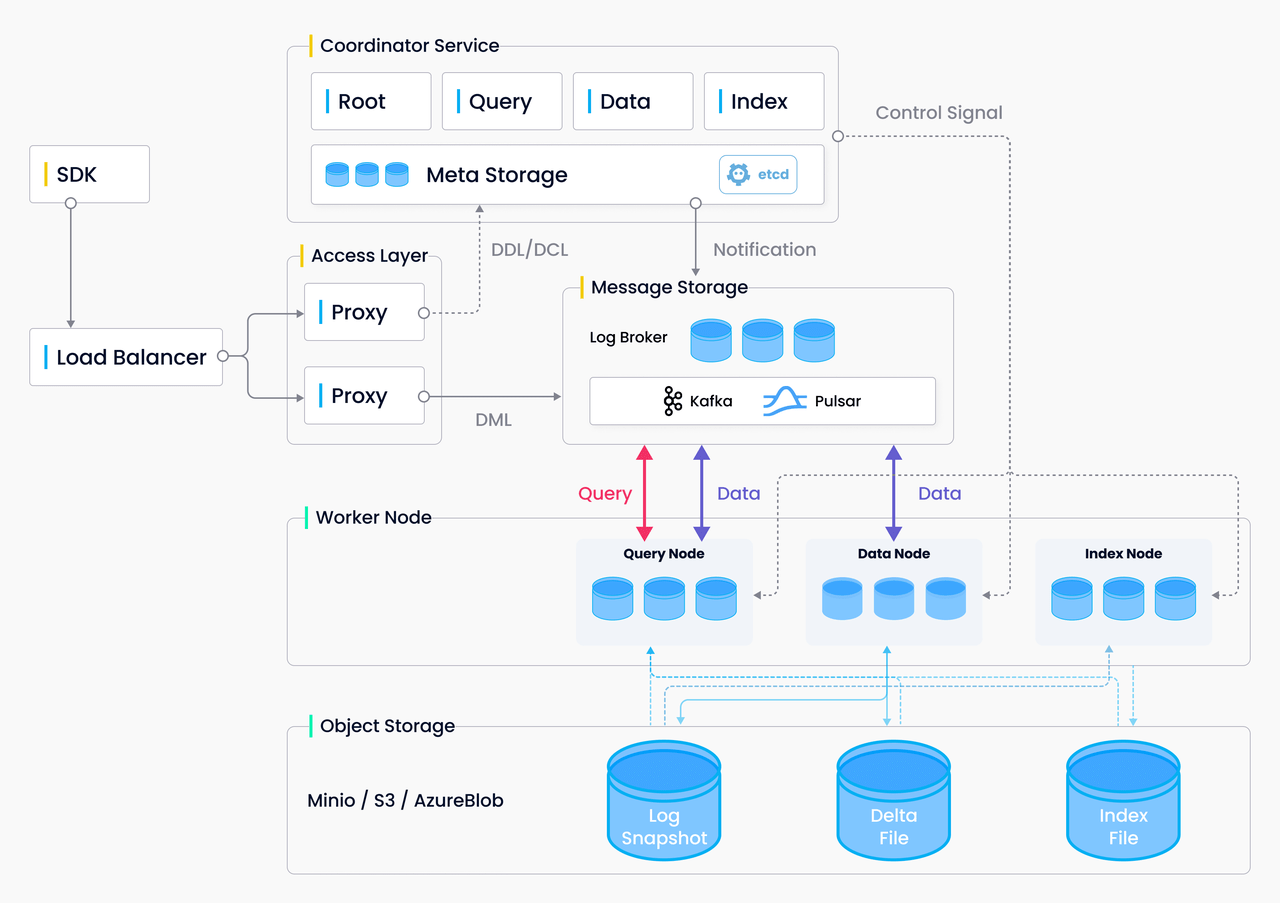
- SDK
- Access Layer
- Coordinator Service
- Metadata storage (ETCD)
- Message Queue (RocksMQ(default), Kafka, Pulsar)
- Worker Node
- Object Storage (MinIO (default), S3, Azure Blob)
Collections in Milvus
- Databases in Milvus
- Each Milvus instance can manage multiple databases. A single instance can have up to 64 databases)
- Default database is
default. It is automatically created. If a new entity is created without a specified database name, it is stored in the default database. - A database is a container for data. It will store collections, partitions, and indexes within it.
- RBAC implemented by database. Users can be created and configured at a database level. Roles can also be created for each database with specified permissions and then assigned to users.
- Multi-tenancy option. Each tenant can be provided with their own database, and data belonging to that tenant can be stored there. This provides the highest level of tenant isolation within a Milvus database.
- Collections in Milvus
- A milvus collection is like a table in traditional databases. It is the logic entry that is used to store and manage data.
- Each collection is created by providing a schema that defines fields for data storage. Schema can also be modified with certain restrictions.
- Fields have datatypes, size, default values
- Scalar and vector datatypes: A give collection can have a combination of scalar and vector fields
- Primary keys and auto-generated keys are available
- Dynamic fields allowed ad hoc fields to be added
Scalar datatypes: INT8, INT16, INT32, INT64, FLOAT, DOUBLE, VARCHAR, BOOL, JSON, ARRAY
Vector datatypes: BINARY_VECTOR, FLOAT_VECTOR
Partitions in Milvus
- Each collection can bee split up as multiple partitions
- Data in the same partition is stored physically together
- Default partition is _default
- 可以指定从特定partition存取 Data can be inserted to and queried from partitions specially
- Partition keys can be used for automatic allocation
- Partition help optimize storage and search options
Indexes in Milvus
Indexes help speed up search operations
Create on scalar or vector fields
One index only per field
Organizes vectors based on the approximate nearest neighbor (ANN) metrics type chosen (L2, IP)
Indexes is the prerequisite for doing ANN searches
Index Types
Type Use FLAT Small dataset, 100% recall rate IVF_FLAT Large dataset, fast query, high recall rate GPU_IVF_FLAT Same as IVF_FLAT, for GPUs IVF_SQ8 Fast query with limited resources IVF_PQ Fast query, limited resources, and low recall rate HNSW Fast query, high recall, high memory SCANN Fast query, high recall, high memory
Managing Data in Milvus
- Rows are called entities in Milvus
- Bulk inserts possible and recommended
- Flush operation is needed to index newly insert data. Milvus automatically flushes data after then pending records reach a specific size after insertion. But if immediate query is need, it is recommended to manually trigger the flush operation.
- Upsert available based on the primary key. If a duplicated record is inserted with the same primary key, the existing record is updated rather than creating a new record.
- Records can be deleted by a primary key or a boolean expression.
Query and Search in Milvus
- Query
- Scalar-based filtering and retrieval process (like RDBMS)
- Specify output fields, offset and limits
- Restrict query to partitions by partition key or name
Count(*)available to aggregate data, other capacity likesum()oravg()is not available.- Query features are limited compared to RDBMS systems.
- Filters in Query
- Comparison Operators (
>,>=,<,<=,==,!=,in) - Logical Operators (
&&,||) - Match Operators (
like) - Array Operator (
ARRAY_CONTAINS) - JSON Operator (
JSON_CONTAINS) - https://milvus.io/docs/boolean.md
- Comparison Operators (
- Search on Vector Fields
- Search on any vector field using a search query using distance measures.
- An input string can be compared to strings in the database, and related strings can be extracted with semantic search. For this, an input string or the search query should first be converted to a vector using the same embedding model as the one used when ingesting the vector field.
- Metric used should be the same as the index metric (like L2, IP): The metric used for comparison should be the same metric that was used when creating the index for the vector field. Do note that the index is a prerequisite before search can be performed on the vector field.
- Specify limit and offset
- Radius can be used to filter based on similarity (distance). The smaller the distance, the higher the similarity.
- Returns distance to the original query in addition to results
Set up Milvus
https://milvus.io/docs/install_standalone-docker.md
1 | # Download the installation script |
After running the installation script:
- A docker container named milvus has been started at port 19530.
- An embed etcd is installed along with Milvus in the same container and serves at port 2379. Its configuration file is mapped to embedEtcd.yaml in the current folder.
- The Milvus data volume is mapped to volumes/milvus in the current folder.
3. Milvus Database Operations
Create a connection
1 | !pip install pymilvus==2.3.5 |
Connecting to Milvus
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#Creating a connection
#Import the pymilvus package
from pymilvus import connections
#Create list of connections
connections.add_connection(
#Specify a name for the connection
learn={
"host": "localhost",
"port": "19530",
"username" : "",
"password" : ""
})
#Connect
connection_id="learn" # connection name for future reference
connections.connect(connection_id)
#List all connections
connections.list_connections()
Create databases and users
1 | #Database operations |
output:
1 | Current databases: ['default'] |
Create a new user:
1 | #user management |
We can access 192.168.3.4:19530 - Attu to view the database and user.
Create collections
1 | from pymilvus import CollectionSchema, FieldSchema, DataType, Collection |
Inserting data into Milvus
1 | #read the input course CSV |
1 | #Use langchain to create embeddings. |
1 | #Prepare data for insert |
1 | #Initiate a collection object and insert data |
Build an index
1 | #Build an index |
nlist: the number of clusters or buckets to create the index. Higher values of this parameter can lead to better efficiency but lower search effectiveness.
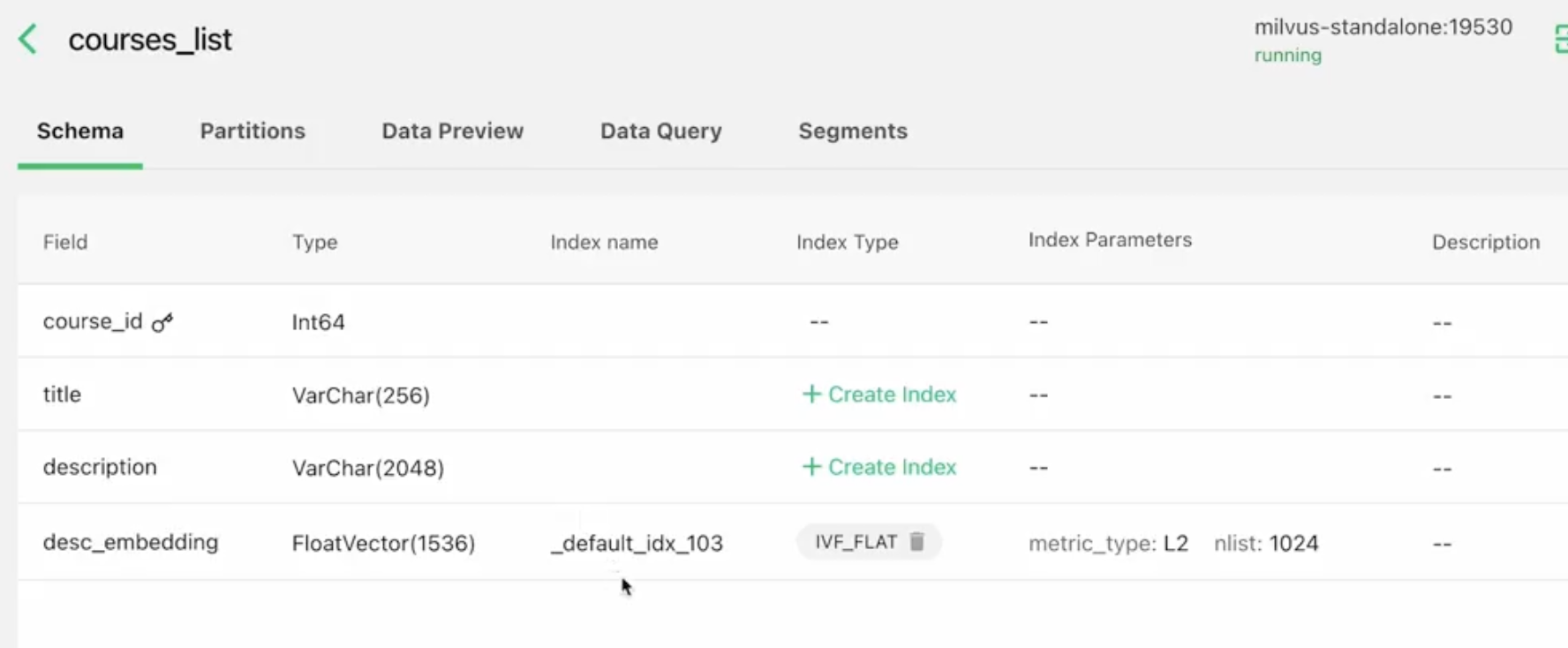
Querying scalar data
1 | #Load the Collection |
1 | q_result= course_collection.query( |
1 | q_result2= course_collection.query( |
Searching vector fields
1 | #Make sure that the collection is already loaded. |
ignore_growing: whether the search should ignore segments that are not fully populated. Milvus internally processes data in segments. If set to true, the search may ignore some newly added data. Setting it to false would also include all new data at an additional query cost.nprobeindicates the number of clusters to search starting from the most matching records cluster. Reducing nprobe helps in efficiency, but may possibly ignore additional matches beyond the number of clusters searched.consistency_levelcontrols whether data in processing will be considered for the search.
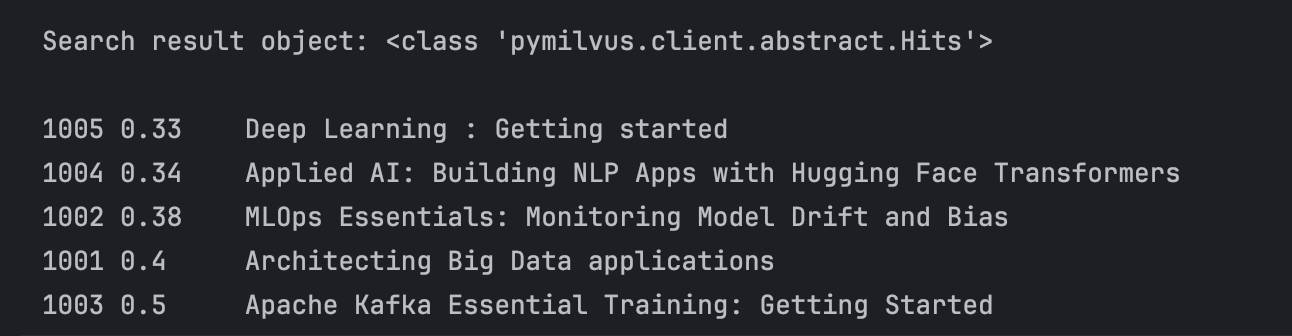
1 | #Search an unrelated query |

So how do we ensure that we get results that are similar to the search string? We need to use the distances returned and use a similarity cut off threshold.
Deleting objects and entities
1 | #Delete a single record |
1 | #Drop a collection |
1 | #drop a database |
4. Vector DB for LLM Query Caching
LLMs and Caching
Shortcomings with Using LLMs and how vector DB can help:
- LLMs have revolutionized the use of AI
- Several apps are being built with LLMs in the backend
- LLMs are expensive to build, deploy, maintain, and use
- Cost per inference call is high
- Latency per inference is also high, given the nature of LLMs
How caching help?
- In a given organization or context, users trigger similar prompts to the LLM, resulting in the same responses
- Caching prompts and responses and serving similar prompts from the cache helps reduce cost and latency
- Prompt/response caching is becoming an essential component of generative AI applications
Prompt caching workflow
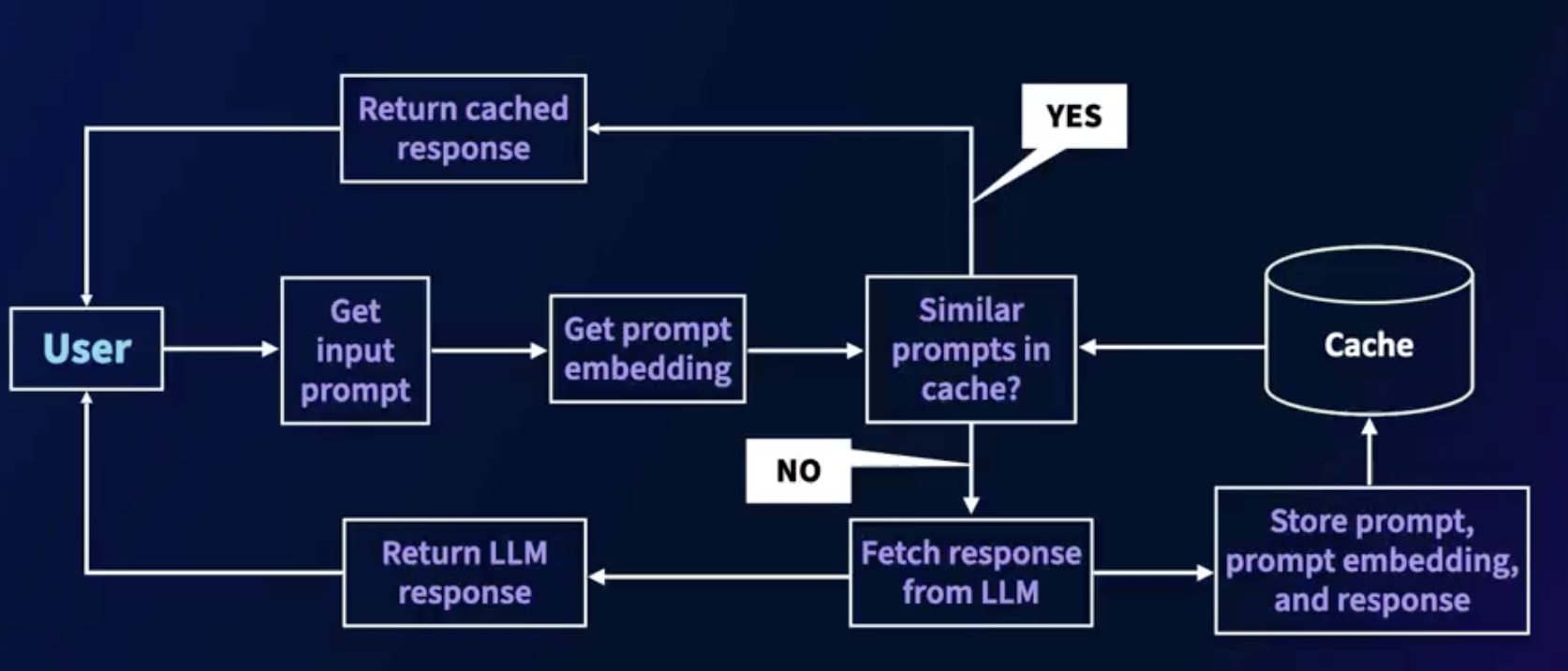
Set up the Milvus cache
1 | #Setup database & collection |
1 | #Create a Collection for cache |
Inference processing and caching
1 | from transformers import AutoTokenizer |
radius: Only matches with distances less than the threshold
1 | #Build up the cache |
1 | response=get_response("List some advantages of the python language") |
Cache management
- Track cache hit ratio to measure cache effectiveness
- Benchmark/test to find the right similarity threshold (radius)
- Limit size of cached entries
- Track last used timestamp (another scalar)
- Prone entries based on age, last used
- Get user feedback to measure if cached answers are accurate
5. Introduction to Retrieval Augmented Generation (RAG)
LLM as a knowledge source
LLM capabilities:
- Language capabilities: Understanding, reasoning, generating, and translating text
- Knowledge capabilities: Question answering, knowledge distillation
LLM as a Knowledge Base: shortcomings
- can only answer questions based on the data they are trained on
- Answers may not be current
- LLMs can hallucinate
- Cannot answer based on enterprise/confidential data
- Building custom LLMs/fine-tuning with organizational
Introduction to retrieval augmented generation (RAG)
Retrieval augmented generation (RAG) is a framework that combines knowledge from a curated (精心策划的)knowledge base with the generation capabilities of an LLM to provide accurate and well-structured answers.
When users provide prompts, the knowledge base provides contextual knowledge and the LLM provides well-structured answers.
- RAG Features
- Use enterprise and confidential data sources
- Combined data from multiple data sources in different formats
- Curate/prune data to ensure up-to-date and accurate knowledge
- To find answers to queries, we can combine scalar and vector searches. Vector searches can be used to find relevant answers in vectors, while scalar filters can help with narrowing down the context. For example, if the user asks a troubleshooting question about a specific product, scalar filters can be used to filter answers for that specific product.
- RAG can use standard and out-of-the-box LLMs for language generation without the need to create or fine-tune custom models. This significantly reduces the cost.
RAG: Knowledge curation process
How do we build a RAG systems?
- The knowledge curation process
- The inference process
The knowledge curation process:
We can have one or more sources of data for the RAG system. This could be websites, ticket system, traditional RDBMS databases, document hubs like SharePoint or Google Drive, and a Doc documents.
Do note that the structure of the data sources will be vastly different. For each of these data sources, we need to build an acquisition module. The module will fetch data from the sources, filter it for relevant information, and then cleanse them to eliminate any kind of noise.
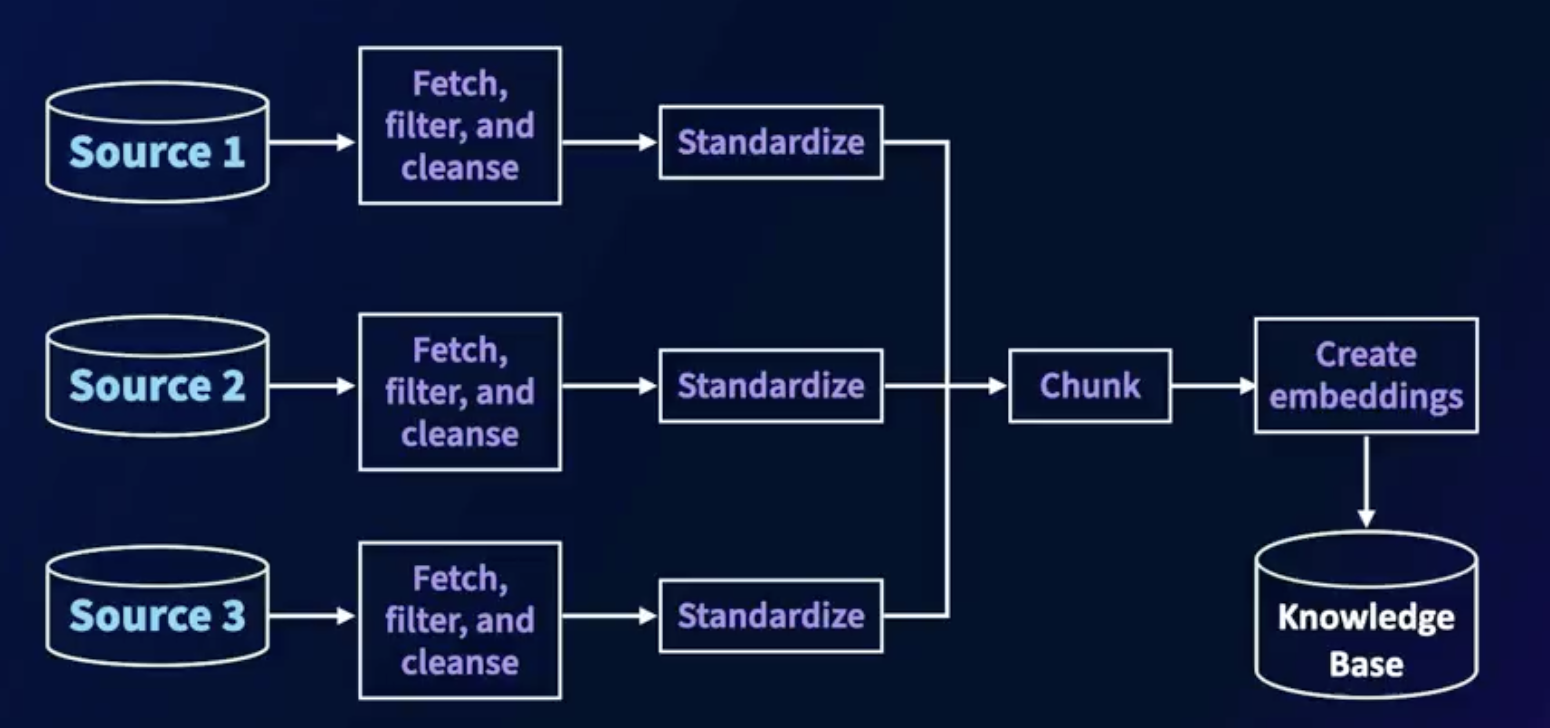
RAG question-answering process
Applications of RAG
- Interactive chatbots
- Automated email responses for customer queries
- Root cause analysis (based on observations and manuals)
- Ecommerce search
- Automated help desks (HR, legal, logistics)
- Document hub searches
6. Implementing RAG with Milvus
Set up Milvus for RAG
1 | #Create the Connection and database for RAG |
1 | #Create a new collection for RAG |
Prepare data for the knowledge base
1 | #Load up the PDF document |
1 | #Split document into chunks |
1 | #create embeddings |
Populate the Milvus database
1 | insert_data=[record_ids, rag_text, rag_embedding] |
Answer questions with RAG
1 | #The retrieval process |
1 | #Prepare prompt for LLM |
1 | #Generate with LLM |
7. Vector Databases Best Practices
Choose a vector database
- Several vector DB options available
- Cloud vs standalone, embedded vs cluster, specialized vs general
- Use case decides the choice of the database
- Storage, scalability and reliability needs
- Frequency of hybrid queries
- OK to store data in the cloud?
- Can provide resources for local hosting and management?
Combine vector and scalar data
- Specialized vector databases
- Excellent support for vector search
- Lack the extensive query capabilities that traditional databases provide
- Does the use case require hybrid search?
- Keep scalar and vector data in separate databases?
- Choose carefully, since it has significant implications
Distance measure considerations
- Vector search will always return hits as long as there are records available in the database. If we set a limit of 10 in the query, it will return 10 records as long as there are 10 records in the database.
- Distance or similarity thresholds needs to check if vectors in DB match the vector in query. In Milvus, we can set the radius search parameter to this value.
- What exactly is similar? Depends on the use case.
- Embedding models and metric type impact similarity thresholds
- Custom embedding by domain (examples: healthcare, finance)
Tune vector DB performance
- Effectiveness of search depends upon the search data, embedding model, metric type, and thresholds
- Find the best combination by experimentation
- Use a good test dataset that matches real-word data
- Experiment with embedding models and metric types
- Experiment with different distance thresholds to find the optimal value
- Continue to monitor this performance in production also
Conclusion
Keep exploring:
- Other vector database products beyond Milvus to understand how they compare
- Tools like LangChain and LlmalIndex help in building applications with vector databases
- Retrieval augmented generation application for your organization with vector databases