Fine tuning improves the overall performance of a model for your particular use case. The responses to your prompts are improved when using a fine tuned model.
You can reduce token costs because your prompts are shorter and require fewer examples than few shot prompting or retrieval augmented generation or RAG
The model responds to your queries (prompts) faster with lower latency.
Fine-tuning process
Obtain the data: a minimum for 10 examples is required. 50-100 training examples will clearly improve the fine-tuning
Prepare the data: Format your data in the JSONL format.
Upload the data to the OpenAI server: Use the Files API to upload your data.
Create a fine-tuning job: Use the OpenAI API, SDK, or option in the Playground.
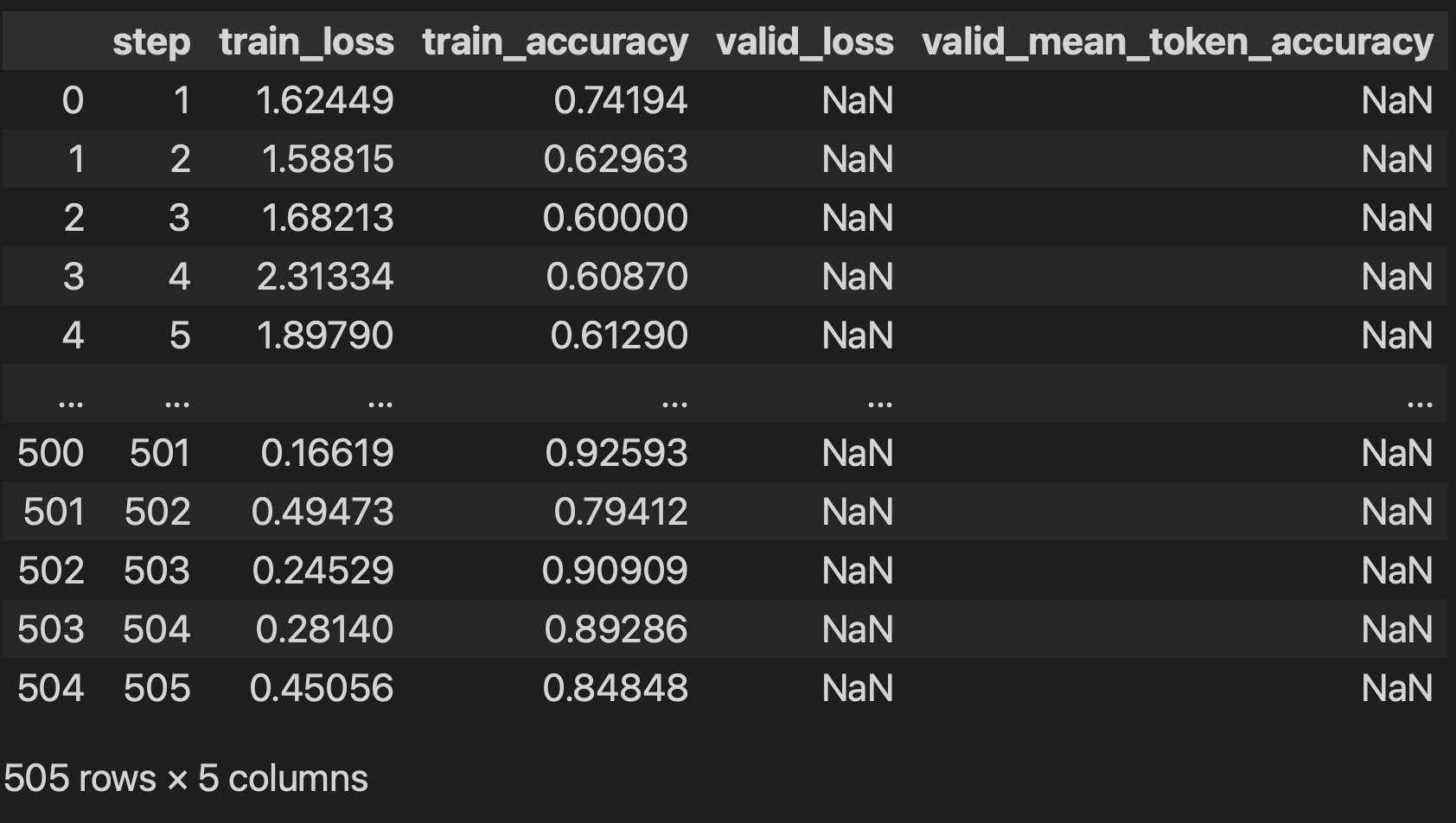
Evaluate the model: Use metrics like training loss and training token accuracy.
Use the model: Use in the model parameter of your ChatCompletions call
Understand the costs of the fine-tuning
OpenAI charges you based on tokens, the input and output tokens will be charged.
Fine-tuned prompt allows you send short tokens.
Getting to know the number of tokens helps 1. estimate the costs; 2. reduce the latency
Pricing
Training the fine-tuned model (base price * token * epoch)
Providing the specific name of the business in the dataset is important for the fine-tuning. Since we are teaching the model to answer questions.
Prompts to generate dataset
1 2 3
Customer Support Automation Automating responses to customer inquiries on various platforms (email, chatbots, social media). Collect a dataset of customer inquiries and manually crafted responses. This dataset should cover a wide range of common questions, complaints, and feedback, along with the company's standard responses. Ensure to anonymize personal information.
import json import tiktoken # for token counting import numpy as np from collections import defaultdict
encoding = tiktoken.get_encoding("cl100k_base")
#input_file=formatted_custom_support.json ; output_file=output.jsonl defjson_to_jsonl(input_file, output_file): # Open JSON file f = open(input_file) # returns JSON object as # a dictionary data = json.load(f) # produce JSONL from JSON withopen(output_file, 'w') as outfile: for entry in data: json.dump(entry, outfile) outfile.write('\n')
defcheck_file_format(dataset): # Format error checks format_errors = defaultdict(int) for ex in dataset: ifnotisinstance(ex, dict): format_errors["data_type"] += 1 continue messages = ex.get("messages", None) ifnot messages: format_errors["missing_messages_list"] += 1 continue for message in messages: if"role"notin message or"content"notin message: format_errors["message_missing_key"] += 1 ifany(k notin ("role", "content", "name", "function_call") for k in message): format_errors["message_unrecognized_key"] += 1 if message.get("role", None) notin ("system", "user", "assistant", "function"): format_errors["unrecognized_role"] += 1 content = message.get("content", None) function_call = message.get("function_call", None) if (not content andnot function_call) ornotisinstance(content, str): format_errors["missing_content"] += 1 ifnotany(message.get("role", None) == "assistant"for message in messages): format_errors["example_missing_assistant_message"] += 1 if format_errors: print("Found errors:") for k, v in format_errors.items(): print(f"{k}: {v}") else: print("No errors found")
# not exact! # simplified from https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb defnum_tokens_from_messages(messages, tokens_per_message=3, tokens_per_name=1): num_tokens = 0 for message in messages: num_tokens += tokens_per_message for key, value in message.items(): num_tokens += len(encoding.encode(value)) if key == "name": num_tokens += tokens_per_name num_tokens += 3 return num_tokens
n_billing_tokens_in_dataset = sum(min(MAX_TOKENS_PER_EXAMPLE, length) for length in conversation_length) print(f"Dataset has ~{n_billing_tokens_in_dataset} tokens that will be charged for during training") print(f"By default, you'll train for {n_epochs} epochs on this dataset") print(f"By default, you'll be charged for ~{n_epochs * n_billing_tokens_in_dataset} tokens")
# Retrieve job status job_id = "ftjob-ts4hC5Qakf2XzytcGrTW0GRZ"
# Retrieve the state of a fine-tune # Status field can contain: running or succeeded or failed, etc. client.fine_tuning.jobs.retrieve(job_id)
Use a fine-tuned model
base model:
1 2 3 4 5 6 7 8
response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": "This is a customer support chatbot designed to help with common inquiries.", "role": "user", "content": "What is the return policy at Kesha's Boutique?"} ] ) print(response.choices[0].message.content)
output:
1
I apologize, but as an AI language model, I do not have access to specific information about the return policy at Kesha's Boutique. To find out about their return policy, I recommend visiting their official website or contacting their customer service directly.
response = client.chat.completions.create( model=fine_tuned_model, messages=[ {"role": "system", "content": "This is a customer support chatbot designed to help with common inquiries for Kesha's Boutique.", "role": "user", "content": "What is the return policy at Kesha's Boutique?"} ] ) print(response.choices[0].message.content)
output:
1
Our return policy allows customers to return items within 30 days of purchase for a full refund, as long as the items are in their original condition. Sale items and certain products may have different return conditions, so please check our return policy page for more details.
#sets the persona for the AI assistant using a system message context = [{'role':'system', 'content': """This is a customer support chatbot designed to help with common inquiries for Kesha's Boutique."""}]
defcollect_messages(role, message): #keeps track of the message exchange between user and assistant context.append({'role': role, 'content':f"{message}"})
#Start the conversation between the user and the AI assistant/chatbot whileTrue: collect_messages('assistant', get_completion()) #stores the response from the AI assistant user_prompt = input('User: ') #input box for entering prompt if user_prompt == 'exit': #end the conversation with the AI assistant print("\n Goodbye") break collect_messages('user', user_prompt) #stores the user prompt
5. Evaluating a Fine-Tuned Model
Evaluate a fine-tuned model
When retrieving job status, you’ll get the FineTurningJob which contains result_file attribute if the job is succeeded.
1 2 3 4 5 6
# Retrieve job status job_id = "ftjob-ts4hC5Qakf2XzytcGrTW0GRZ"
# Retrieve the state of a fine-tune # Status field can contain: running or succeeded or failed, etc. client.fine_tuning.jobs.retrieve(job_id)