2024.06.02 PyTorch Essential Training
1 | Status: Finished |
Use Google Colab: https://colab.research.google.com/
https://colab.research.google.com/drive/1VHaPSHXGrLlJ5dzC628OVogfY4f8w2mZ
Tensors
Introduction to Tensors
We can think Tensor is generalizations of scalars, vectors, and matrices to any dimension
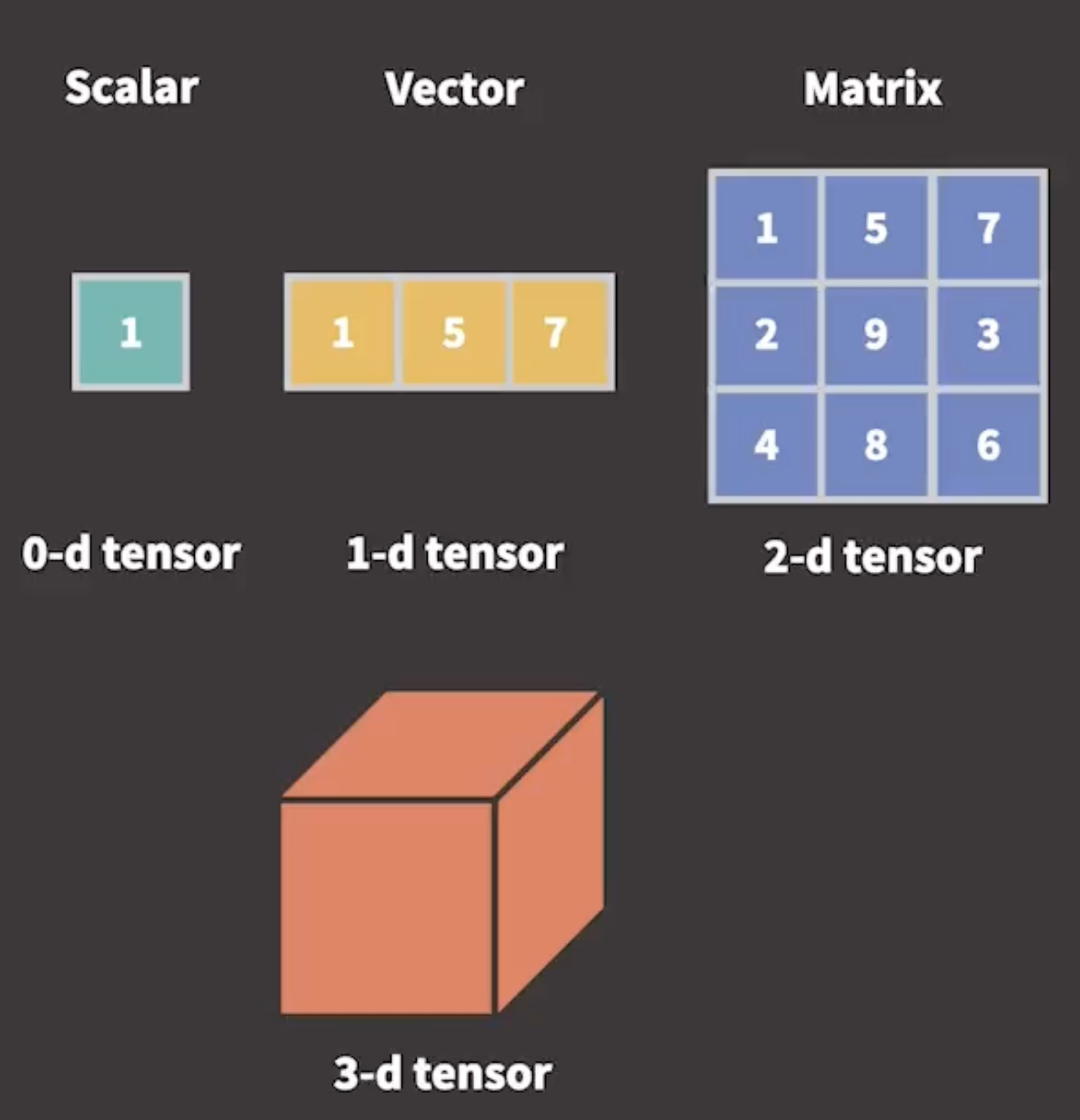
Tensor vs ndarray
Advantages of Tensors
- Tensor operations are performed significantly faster using GPUs
- Tensors can be stored and manipulated at scale using distributed processing on multiple CPUs and GPUs and across multiple servers
- Tensors keep track of the graph of computations that created them
Creating a tensor CPU example
1 | import torch |
output:
1 | tensor([[13, 12, 14, 13], |
1 | sub_tens = first_tens - second_tens |
output:
1 | tensor([[11, 8, 8, 5], |
Creating tensors GPU example

1 | import torch |
1 | tens_a = torch.tensor([[10, 11, 12, 13], [14, 15, 16, 17]], device=device) |
output:
The result is also allocated in GPU. The cuda:0 means the first GPU is used. In the case our device contains multiple GPUs, this way, we can controle which GPU is being used.
1 | tensor([[180, 209, 240, 273], |
Moving Tensor between GPUs and CPUs
By default, all the data are in the CPU
When training neural network, which is huge, we prefer to use GPU for faster training
Transfer the data from the CPU to the GPU
After the training, the output tensors are produced in GPU
The output data requires preprocessing
Some preprocessing libraries don’t support tensors and expect a NumPy array
NumPy supports only data in the CPU; we need to move the data from the CPU to the GPU
Moving Tensors from CPU to GPU
1
2
3
4
5
6
7
8# 1st way
Tensor.cuda()
# 2nd way
Tensor.to("cuda")
# 3rd way
Tensor.to("cuda:0")Moving Tensors from GPU to CPU
1
2
3
4
5# 1st case Tensor with required_grad = False
Tensor.cpu()
# 2nd case Tensor with required_grad = True
Tensor.detach().cpu()
Creating Tensors
Different ways to create tensors
http://pytorch.org/docs/stable/torch.html
1 | import torch |
1 | # initialize a tensor from a ndarry |
Different functions for creating tensors
torch.empty(),torch.ones(),torch.zeros()1
2
3
4
5
6tensor_emp = torch.empty(3, 4)
print("tensor_emp :", tensor_emp)
tensor_zeros = torch.zeros(3, 4)
print("tensor_zeros :", tensor_zeros)
tensor_ones = torch.ones(3, 4)
print("tensor_ones :", tensor_ones)torch.rand(),torch.randn(),torch.randint()- uniform distribution: 均匀分布
- normal distribution: 正态分布
1
2
3
4
5
6
7
8
9
10
11
12# tensors initialized by size with random values
# returns a tensor filled with random numbers from a uniform distribution
tensor_rand_un = torch.rand(4, 5)
print("tensor_rand_un :", tensor_rand_un)
# returns a tensor filled with random numbers from a normal distribution
tensor_rand_norm = torch.randn(4, 5)
print("tensor_rand_norm :", tensor_rand_norm)
# returns a tensor filled with random integers generated uniformly (from 5 to 10)
tensor_rand_int = torch.randint(5, 10, (4, 5))
print("tensor_rand_int :", tensor_rand_int)output:
1
2
3
4
5
6
7
8
9
10
11
12tensor_rand_un : tensor([[0.8624, 0.2577, 0.8981, 0.7393, 0.1189],
[0.1564, 0.9084, 0.1446, 0.2822, 0.2021],
[0.7456, 0.3061, 0.0126, 0.9152, 0.3011],
[0.1059, 0.9894, 0.9812, 0.8815, 0.9442]])
tensor_rand_norm : tensor([[-1.1702, 1.5030, -1.2549, -0.1946, 0.9323],
[ 0.3549, -0.2362, 0.2905, 0.6290, -0.4099],
[-1.1625, 1.6882, 0.6824, -0.3181, 0.8423],
[-0.8305, -0.5503, 0.0125, 1.0829, -0.5804]])
tensor_rand_int : tensor([[7, 6, 5, 7, 9],
[7, 8, 9, 7, 6],
[7, 5, 6, 6, 5],
[9, 9, 7, 6, 8]])1
2
3# initialize a tensor of ones
tensor_ones = torch.ones_like(tensor_rand_int)
print(tensor_ones)output
1
2
3
4tensor([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]])
Tensor attributes
Knowing device location, datatype, dimension, and rank is very important
1 | import torch |
torch.device indicates the tensor’s device location
1 | first_tensor.device |
torch.dtype indicates the tensor’s data type
1 | first_tensor.dtype |
torch.shape shows the tensor’s dimensions
1 | first_tensor.shape |
torch.ndim identifies the number of a tensor’s dimensions or rank
1 | first_tensor.ndim |
Tensor data types
Integer data type tensor
1 | #@title Integer data type tensor |
Float data type tensor
1 | #@title Float data type tensor |
Short data type tensor
1 | #@title Short data type tensor |
Casting a tensor to a new data type (1st way)
1 | #@title Casting a tensor to a new data type (1st way) |
Casting a tensor to a new data type (2nd way)
1 | #@title Casting a tensor to a new data type (2nd way) |
Creating tensors from random samples
1 | torch.manual_seed(111) # fixed seed |
Creating tensors like other tensors
torch.zeros_like(), torch.ones_like(), torch.rand_like()
1 | torch.full((4, 5), 5) # a array with all 5 |
Manipulate Tensors
Tensor operations
Indexing and slicing of tensors is the same way with NumPy
1 | #@title Indexing 1-dim tensor example |
1 | #@title Slicing 1-dim tensor example |
1 | #@title Indexing 2-dim tensor example |
1 | #@title Slicing 2-dim tensor example |
1 | #@title Use indexing to extract the data that meets some criteria |
1 | #@title Combining tensors 维度增加 |
1 | #@title Concatenation 维度不变,shape增大 |
1 | #@title Splitting tensors |
1 | #@title Splitting 2-dim tensor |
Mathematical functions
Built-In Math Functions
Pointwise operation
Reduction functions
Comparison function
Linear algebra operation
Spectral and other math computations
Pointwise operation
Perform an operation on each point in the tensor individually and return a new tensor
- Basic math functions:
add(),mul(),div(),neg(), andtrue_divide() - Functions for truncation:
ceil(),clamp(),floor(), etc. - Logical function
- Trigonometry function (三角函数)
- Basic math functions:
Reduction Operations
Reduce numbers down to a single number or a smaller set of numbers
- Results in reducing the dimensionality or rank of the tensor
- Include statistical functions such as mean, median, mode, etc.
Comparison Functions
- Compare all the values within a tensor or compare values of two different tensors
- Functions to find the minimum or maximum value, sort tensor values, test tensor status or condition, and similar
Linear Algebra Functions
torch.mm(),torch.matmul(),torch.bmm()- Enable matrix operations and are essential for deep-learning computations
- Functions for matrix computations and tensor computations
Spectral Operations
Useful for data transformations or analysis
1 | #@title Basic math function |
1 | #@title Reduction functions |
Linear algebra operations
http://pytorch.org/docs/stable/linalg.html
PyTorch has a module called torch.linalg that contains a set of built-in algebra functions that are based on BLAS and LAPACK standardized libraries
1 | #@title Compute the dot product (scalar) of two 1d dimensions |
1 | #@title Compute the matrix-matrix product (2D tensor) of two 2d tensors |
torch.mm() unlike torch.matmul(), it doesn’t support broadcasting.
1 | #@title Compute the a matrix product of 5 2d tensors 连乘 |
1 | #@title Computing eigenvalues and eigenvectors 特征值和特征向量 |
Automatic differentiation (Autograd)
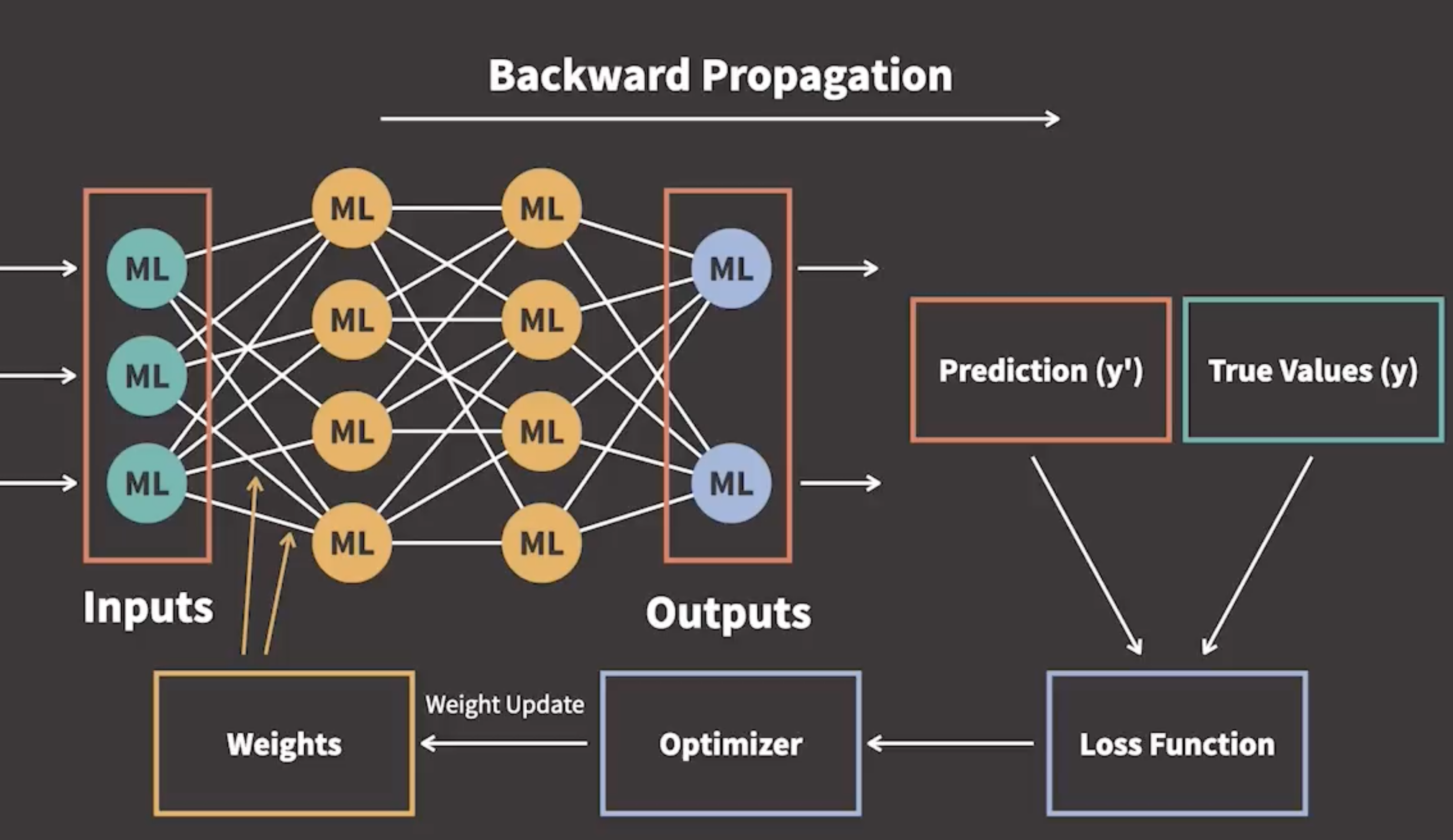
- After we find the loss function, we calculate the derivative of the loss function in terms of the parameters
- We iteratively update the weight parameters accordingly so that the loss function returns the smallest possible loss
- This step is called iterative optimization, as we use an optimizer to perform the update of parameters
- This process is called gradient-based optimization
Automatic differentiation is a set of techniques that allow us to compute gradients for arbitrary complex loss functions efficiently. (自动求偏导)
Numerical Differentiation
- Follows the definition of derivative
- A derivative of
ywith respect toxdefines the rate of change ofywith respect tox
$$
\begin{equation} \frac{\partial y}{\partial x} = \frac{f(x+\Delta x)-f(x)}{\Delta x}\end{equation}
$$
Cons of Numerical Differentiation:
- The computational costs, which increase as we increase the number of parameters in the loss function
- The truncation errors
- The round-off errors
Symbolic Differentiation
- Used in calculus
- Using a set of rules, meaning a set of formulas that we can apply to the loss function to get the gradients
- The derivate of a function $f(x) = 3x^2-4x+5$
- When we apply the symbolic rules, we get $f’(x)=6x-4$
Cons of Symbolic Differentiation:
- Is limited to the already defined symbolic differentiation rules
- It can’t be used for differentiating a given computational procedure
- The computational costs, as it can lead to an explosion of symbolic terms
Automatic Differentiation
refer: computation graph
- Every complex function can be expressed as a composition of elementary functions
- For those elementary functions, we could apply symbolic differentiation, which would mean storing and manipulating symbolic forms of derivatives
- By using automatic differentiation, we don’t have to go through the process of simplifying the expressions
- Instead, evaluate a given set of values
- Another benefit of automatic differentiation is that our function can contain
if-elsestatements,forloops, or recursion.
1 | #@title Define tensors |
Compute gradients
1 | #@title Compute gradients |
Split tensors to form new tensor
The split function enables you to split tensor given the size of the part
The chunk function enables you to split a tensor into a give number of parts
Tensor.chunk(chunks=4, dim=0)Tensor.chunk(chunks=4)Tensor.split([5, 3], dim=0)Tensor.split([4, 6, 6])
Developing a Deep Learning Model
Introduction to the DL training
Data preparation
- The first step in developing a deep learning model
- Consists of loading the data, applying transforms, and batching the data using PyTorch’s built-in capabilities
- Use Python library called Torchvision; it has classes that support computer vision
tochvision.datasetsmodule provides several subclasses to load image data from standard datasets such as our CIFAR-10 dataset
Data loading
1 | #@title Import libraries and dataset |
1 | #@title Load dataset |
1 | #@title Display images |
1 | #@title Examine the training dataset |
1 | #@title Check the class labels |
Data transforms
1 | #@title Import and transform for training data set |
1 | #@title Training data of first image |
1 | (tensor([[[-1.2854, -1.3629, -1.5180, ..., 0.4981, 0.4593, 0.4399], |
1 | #@title Defining transform for testing data set |
Data batching
- A data loader feeds data from the dataset into the neural network
- At the core of PyTorch data loading utility is the
torch.utils.data.DataLoaderclass - It represents a Python iterable over a dataset, with support for:
- Map-style and iterable-style datasets
- Customizing data loading order
- Automatic batching
- Single and multi-process data loading
- The neural network trains best with batches of data
- Instead of using the complete dataset in one training pass, we use mini batches, usually 64 or 128 samples
- Smaller batches require less memory than the entire dataset, resulting in more efficient and accelerated training
- DataLoader has, by default, a
batch_sizeof 1 batch_sizerepresents a number of images that go through the network before we train and update it
1 | from torchvision import transforms |
Model development and training
1 | #@title Import libraries and dataset |
1 | #@title Define neural network, init and forward functions |
1 | #@title Instantiate the Model |
1 | #@title Load and transform the data |
1 | #@title Train the network |
With validation
1 | #@title Train the network |