LLM Foundations: Vector Databases for Caching and Retrieval Augmented Generation (RAG)
Introduction
- Status: Finished
- Author: Kumaran Ponnambalam
- Publishing/Release Date: February 23, 2024
- Publisher: Linkedin
- Link: https://www.linkedin.com/learning/llm-foundations-vector-databases-for-caching-and-retrieval-augmented-generation-rag/genai-with-vector-databases?resume=false&u=3322
- Type: Courses
- Start Date: May 28, 2024
- End Date: June 9, 2024
Scope
- Vector and vector search concepts review
- Concepts and Setup of Milvus DB
- Milvus DB data manipulation and search
- Vector DB as a LLM cache
- Vector DB for Retrieval Augmented Generation (RAG)
Prerequisites
- NLP for Machine learning
- LLM and embeddings
- Python, jupyter notebooks, docker
- LangChain
Introduction to Vector Databases
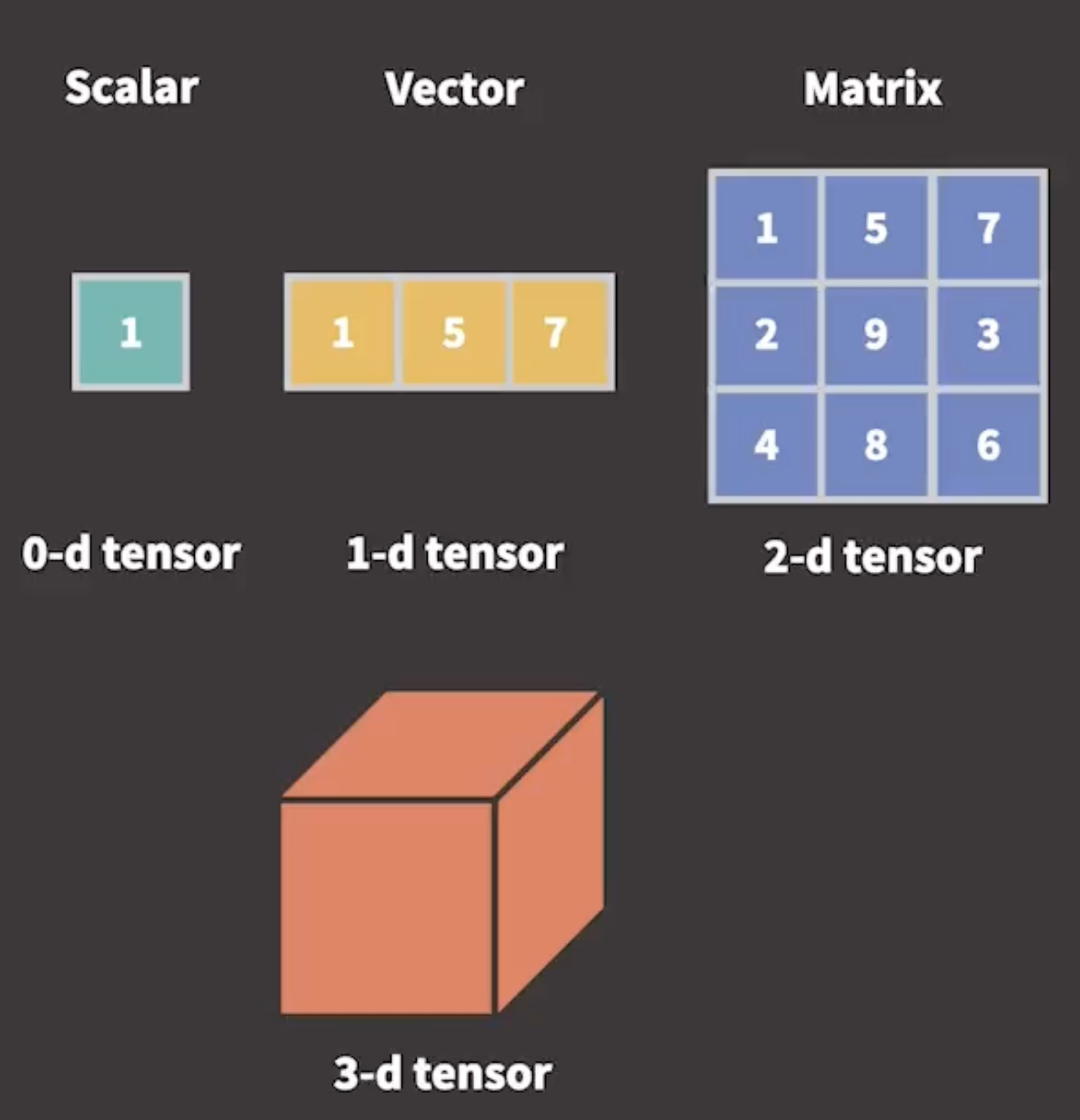
What is a vector?
A vector is an object that has both magnitude (size, quantity) and direction (line, angle, trend)
Vectors in Programming: