理解分布式系统中的一些概念
[TOC]
1. 什么是分布式系统
计算机科学家Andrew S. Tenenbaum对分布式定义为:
A collection of independent computers that appear to its users as one computer
他认为,分布式系统必须要有的三个特征是:
- The computers operate concurrently.
- The computers fail independently.
- The computers don’t share a global clock.
本篇文章包含以下分布式相关的内容:
- Storage(存储): Relational/Mongo, Cassandra, HDFS
- Computation(计算): Hadoop, Spark, Storm
- Synchroniztion(同步): NTP, vector clock(向量时钟)
- Consensus(共识): Paxos, Zookeeper
- Messaging(消息): Kafka
文中会以一个咖啡店业务的发展过程作为例子来进行分布式概念的引入,该咖啡店提供在线业务,从小到大的发展中遇到了各个技术问题,我们一点点进行说明讲解。
2. Read Replication(读副本)
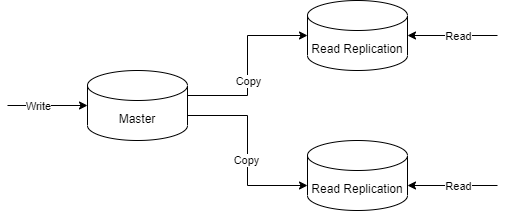
主要适用于主从场景,主节点负责写入,从节点即read replication负责读取。
比如,咖啡店业务刚开始用一个数据库就能支撑订单,但是访问越来越多,我们增加了Read Replication来减轻读压力。
3. Sharding(分片)
假设我们的咖啡店业务做得很好,现在订单越来越多,我们的主库已经出现了不能支撑写的请求。此时我们需要考虑能不能将订单数据进行拆分到几个库里来存储。
Read Replication虽然解决了主节点读的压力,但是对于主节点的写入压力却无能为力。此时,我们考虑使用sharding技术来进行分片,笔者在之前的笔记中也提到过。分片的作用相当于将工作负载(workload)按照一定规则(后面提到的一致性Hash)分配到多个主节点中,由此来均衡压力。
Sharding技术解决了负载压力过大的问题,但是也引入了一些新的挑战:
- More Complexity: 系统更加复杂
- Limited Data Model: 数据需要能够支持分片,比如要有一个key用来做hash
- Limited Data Access Patterns:使用场景更偏向于OLTP,对于OLAP分析类的数据访问,往往需要涉及多维度数据,可能要便利所有shard,此时使用shard没有优势。
4. Consistent Hashing(一致性Hash)
Consistent Hashing也被称为Distributed Hash Table(DHT) ,2007年的Amazon Dynamo论文中采用了这个算法,wikipedia,对其做了比详细的介绍。
在一致性hash下,当HashTable调整大小时,只需要有n/m个数据需要重新映射,其中n是key的数量,m是槽(slot)的数量。相比之下,在大多数传统哈希表中,数组槽数量的变化会导致几乎所有键都被重新映射,因为key和slot之间的映射是由取余操作来实现的。
虽然上面说的解决了scale的问题,但是如果环中的节点出现了故障,则会发生单点问题。前面我们为了避免单点问题,使用read replication。在一致性Hash中,为了避免单点故障,我们沿着环将值存储三分。这样避免了单点问题。
但是在分布式系统领域,解决一个问题往往会引入两个新的问题。
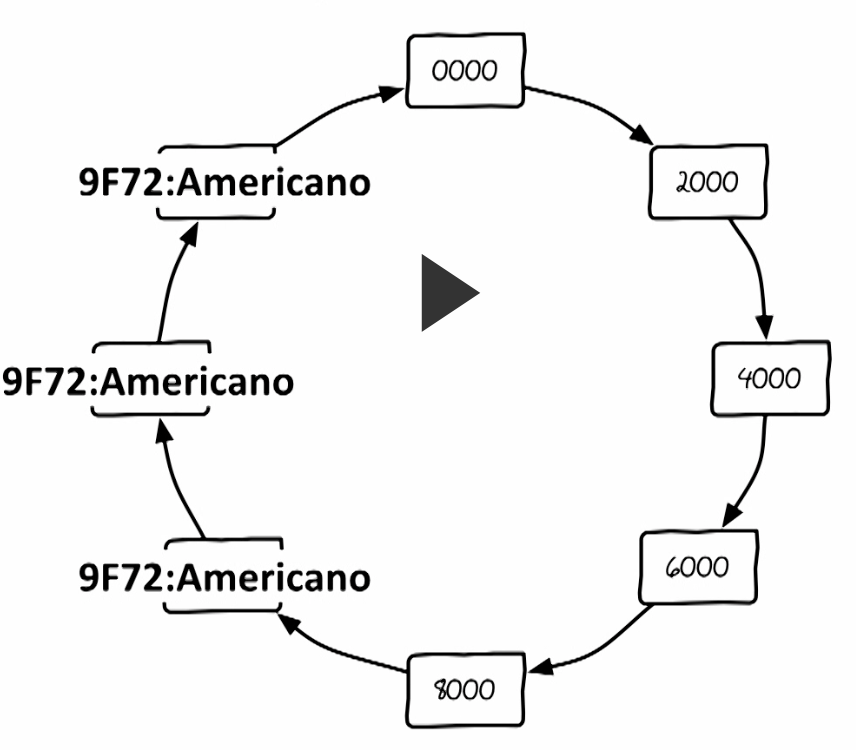
我们为key 9F72 放入了三个副本,现在我想更新对应的值,如果两个更新成功了,一个更新失败了。此时另一个请求来读取值,该怎么来决定读取的值是多少呢?
上面这个问题是一个典型的Consistency(一致性)问题。像Cassandra中使用的是eventual consistency(最终一致性),里面核心的原理就是:
1 | R + W > N |
说明:
N代表副本数量,在上面的例子里,就是3R代表读取时成功的数量W代表写入时成功的数量R + W > N:以上面3个副本为例,写入时我保障半数也就是2个节点已经写入我给的值,读取时有超过半数(也就是2个节点)返回相同的值,那么我获取的值就是一致的,此时2+2>3。
如果一些场景允许不一致,则不需要等待半数以上写入或读取成功,则可以不用上面的最终一致性方案。因为不用等待半数确认,因此,这种方案性能比较高。
综上,使用低延迟非一致性方案还是使用最终一致性方案,取决于业务的使用场景。
上面讲了一致性的问题,对于不一致时该怎么处理呢?这是一个entropy problem(熵问题),对于这类问题,不同的存储系统,比如cassandra, riak, dynamo,采用的方案不一样。
上面我们说了这么多,那什么时候使用基于这些技术的存储系统(比如Cassandra)呢?
- Scale(扩展性)
- Transactional data (会话数据)
- Always on (一直在线)
5. CAP Theorem (CAP理论)
2000年,Eric Brewer在ACM的一个会议上提出分布式数据库不能同时满足Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容忍性)。这个理论就是后来的CAP理论。
- Consistency(一致性):当我读区数据时,读到的永远都是最近一次写入的数据;
- Availability(可用性):当查询时,能取得结果;当写入时,能够写入;而不是说现在不能访问;(When I ask, I get the answer; When I try to write, I can write)
- Partition Tolerance (分区容错性):因为分布式系统存在多个节点,其中的一些节点可能会因为一些原因(比如网络故障)导致不能与其他节点进行通信。当上述发生时,如果节点恢复后,分布式系统能够恢复,这个叫做分区容错性。
因为节点可以随时故障,因此分区容错性是必选的。那剩下的就是在一致性和可用性中选一个了。也就是我们只能实现CP或AP。
CP系统例子:由于网络的原因,节点1不能跟其他节点进行通信,它完全不知道外面数据是什么样子了,此时有个客户端连接了它,并且对它发出获取数据的请求。此时节点1会为了保持一致性而拒绝服务。这就是CP系统。
AP系统例子:由于网络的原因,节点1不能跟其他节点进行通信,它完全不知道外面数据是什么样子了,此时有个客户端连接了它,并且对它发出获取数据的请求。此时节点1如果返回了数据,表现出系统可用的状态。这就是AP系统。
使用CP还是AP,是一个tradeoff。