MapReduce学习笔记
[TOC]
1. MapReduce概述
源自于google的MapReduce论文.
Hadoop MapReduce是Google MapReduce的开源版本。
MapReduce优点:
- 海量数据离线处理
- 易开发
- 易运行
MapReduce缺点:
- 实时流式计算
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
2. MapReduce编程模型
2.1 WordCount
统计文件中每个单词出现的次数。
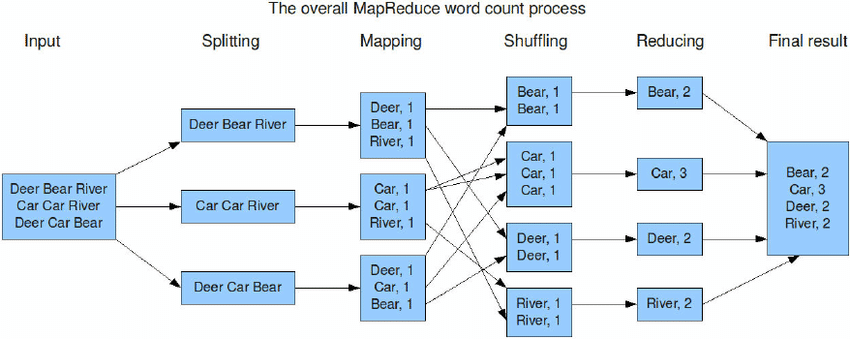
A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
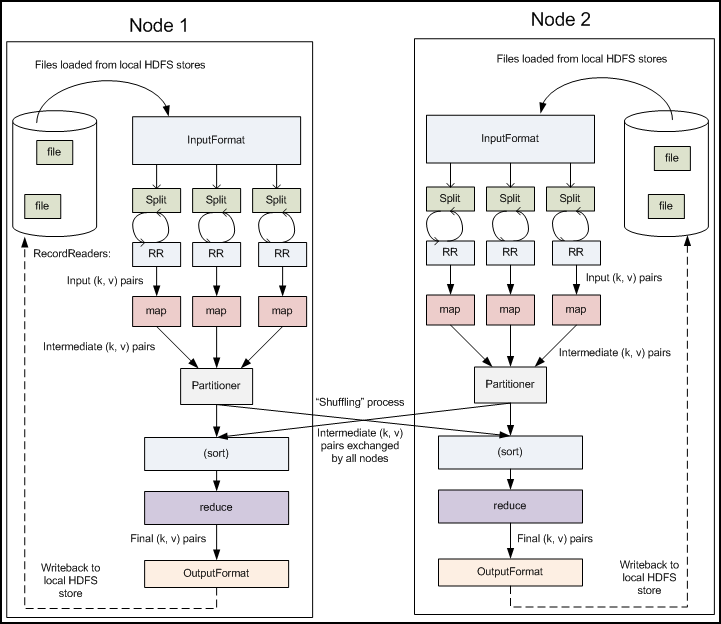
2.2 Map与Reduce阶段
- 作业拆分成Map阶段和Reduce阶段
- Map阶段:Map Tasks
- Reduce阶段:Reduce Tasks
MapReduce执行步骤:
- 逐步map处理的输入数据
- Mapper处理
- Shuffle
- Reduce处理
- 结果输出
The MapReduce framework operates exclusively on <key, value> pairs, that is, the framework views the input to the job as a set of <key, value> pairs and produces a set of <key, value> pairs as the output of the job, conceivably of different types.
The key and value classes have to be serializable by the framework and hence need to implement the
Writableinterface. Additionally, the key classes have to implement theWritableComparableinterface to facilitate sorting by the framework.
2.3 MapReduce核心概念
1.Split:
交由MapReduce作业来处理的数据块,是MapReduce中最小的计算单元。HDFS中的blocksize是HDFS中最小的存储单元(默认128M)。默认情况下,Split与Blocksize是一一对应的,也可以手工设置它们之间的关系(不建议)。
2.InputFormat:
- 将文件的输入数据分片(split):
InputSplit[] getSplits(JobConf job, int numSplits) throws IOException TextInputFormat
3.OutputFormat:
4.Combiner:
5.Partitioner:
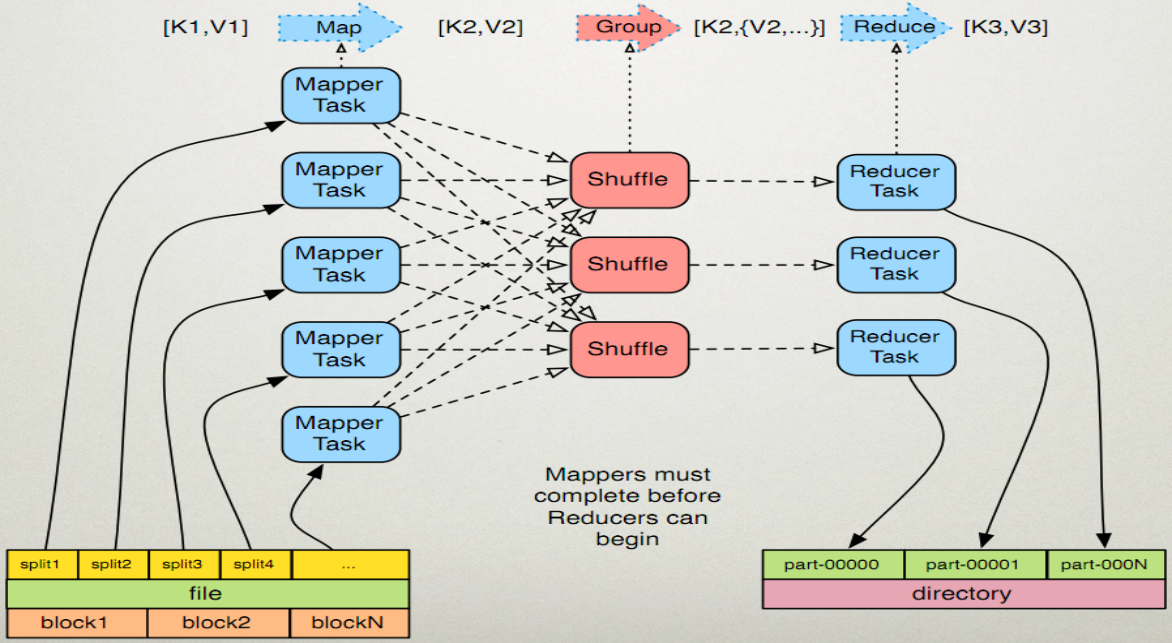
3. MapReduce架构
3.1 MapReduce 1.x架构