Hadoop 101
[TOC]
1. Hadoop概述
Hadoop包含以下模块:
- Hadoop Common: 支撑其他模块的通用工具
- Hadoop Distributed File System(HDFS): 分布式文件系统,提供高吞吐数据读取
- Hadoop YARN: 作业调度与资源管理框架
- Hadoop MapReduce: 基于YARN的大数据并行处理。
开源的分布式存储与分布式计算平台。
1.1 Hadoop能做什么
- 搜索引擎
- 日志分析
- 商业智能
- 数据挖掘
2. Hadoop核心组件
2.1 分布式文件系统HDFS
源于Google的GFS论文,论文发表于2003年10月。
HDFS是GFS的开源实现。
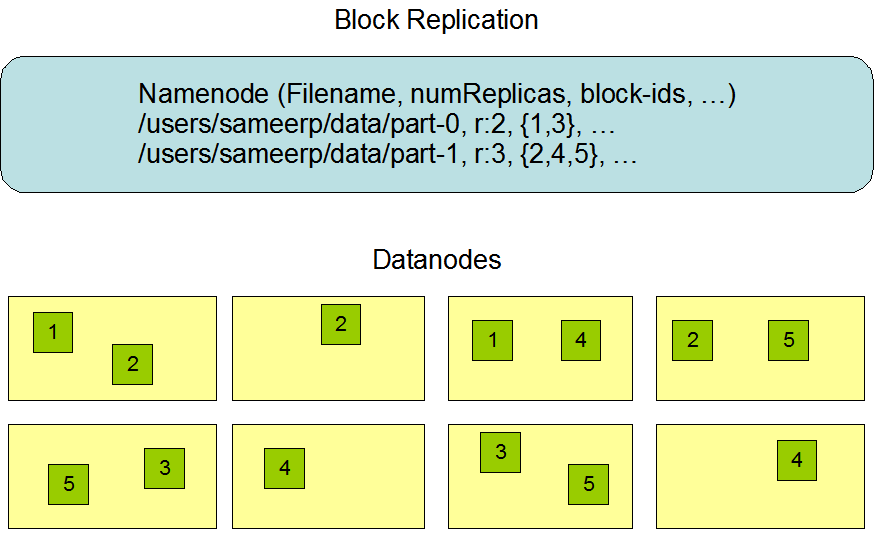
HDFS特点:扩展性、容错性(多副本)、海量数据存储。
在HDFS中,可以将文件切分成指定大小的数据库并以多副本存储在多个机器上。数据库大小默认为128M,可以通过参数进行修改。
数据切分、多副本、容错等操作对用户是透明的。
2.2 资源调度系统YARN
YARN: Yet Another Resource Negotiator
YARN负责整个集群资源的管理和调度
YARN特点:扩展性&容错性&多框架资源统一调度

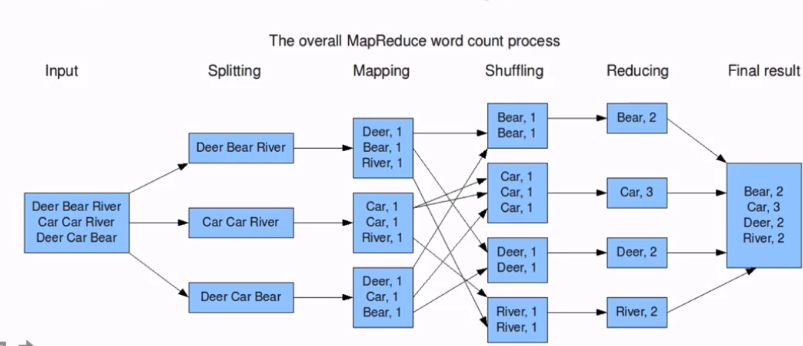
2.3 分布式计算框架MapReduce
源于Google的MapReduce论文,论文发表于2004年12月
MapReduce是Google MapReduce的开源版本。
MapReduce特点:扩展性&容错性&海量数据离线处理
3. Hadoop优势
- 高可靠性
- 数据存储:数据库多副本
- 数据计算:重新调度作业计算
- 高扩展性
- 存储、计算资源不够时,可以横向的线性扩展机器
- 一个集群可以包含数以千计的节点
- 其它
- 存储在廉价机器上,降低成本
- 成熟的生态圈
4. Hadoop生态系统
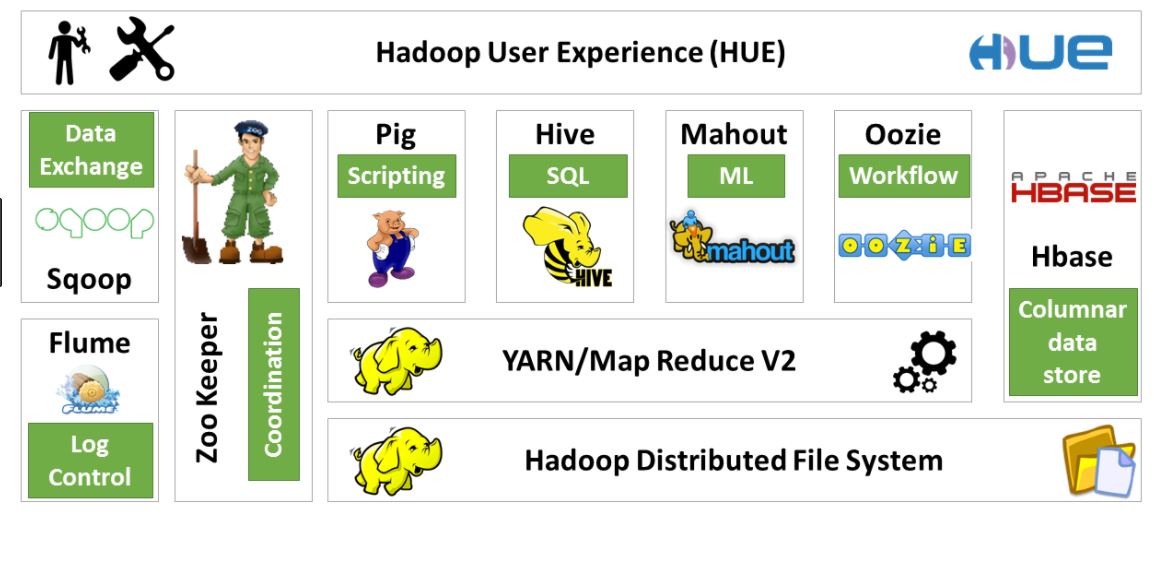
- HDFS:存储数据
- MapReduce/YARN
- Hive: 结构化数据,HQL
- Mahout:机器学习,现在主要面向Spark更新
- Pig: 脚本,离线分析
- Oozie: 工作流引擎
- Zookeeper: 分布式协作服务。解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
- Flume:日志收集
- Sqoop: Sql to Hadoop。主要用于传统数据库和hadoop之间传输数据。数据的导入和导出本质上是mapreduce程序,充分利用了MR的并行化和容错性。
- HBase:HBase是一个针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。和传统关系型数据库不同,hbase采用了bigtable的数据模型。
6. Hadoop发现版本选择
- Apache Hadoop
- CDH: Cloudera Distributed Hadoop
- HDP: Hortonworks Data Platform